
嘉峪检测网 2024-11-24 21:07
导读:本文从基本概念出发,介绍和解释ChatGPT用到的一系列关键技术,如机器学习、神经网络、大模型、预训练+微调范式、Scaling Law……
本文从基本概念出发,介绍和解释ChatGPT用到的一系列关键技术,如机器学习、神经网络、大模型、预训练+微调范式、Scaling Law……希望帮助读者更为深入地了解和使用以ChatGPT为代表的相关工具,助力读者成为人工智能时代的弄潮儿。
2022年11月30日,一家名不见经传的公司(OpenAI)悄悄上线了一个产品ChatGPT。彼时,谁也没有想到这款产品会在短短几个月内风靡全球;而2023年3月14日GPT-4的发布更是激起了一场属于生成式人工智能(artificial intelligence generated content, AIGC)的科技革命。对于普通人来说,面对这个正在给生产和生活带来巨大改变的人工智能产品,不禁会产生无数的疑问:
●ChatGPT为什么引起如此大的重视?
●它的原理是什么?
●它真的具备人类的智慧吗?
●它将给人类社会带来哪些变化?
……
ChatGPT原理概览:文字接龙游戏
ChatGPT最令人印象深刻的能力是它能够通过对话的方式回答用户的问题,那么ChatGPT回答问题的原理是什么呢?传统的问答系统本质上是基于数据库和搜索引擎,即通过搜索引擎在网络与数据库中搜索相关信息,然后把结果直接返回给用户。比如我们使用百度搜索“机器学习的原理是什么”,百度会跳转出各式各样的网站。这些网站是由各个企业早就开发好的,百度仅仅是根据相关度做了一个排序。
不同于传统问答系统中答案来源于现成的网络或者数据库,ChatGPT的回答是随着提问的进行自动生成的。这一点有点像文字接龙游戏,ChatGPT会基于前面的话不断地生成下一个合适的词汇,直到觉得不必继续生成为止。
比如我们问ChatGPT:“苹果是一种水果吗”,ChatGPT会基于这句话进行文字接龙,大概流程如下:
(1)考虑下一个可能的词汇及其对应的概率,如右表(为了方便理解只写了3个可能的形式)所示。
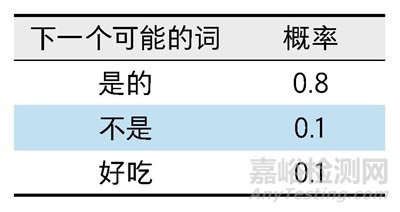
(2)基于上述概率分布,ChatGPT会选择概率最大的答案,即“是的”(因为其概率0.8明显大于其他选项)。
(3)此时这句话的内容变成 “苹果是一种水果么?是的”,ChatGPT会看下一个可能的词和对应概率是什么。
不断重复这个步骤,直到得到一个完整的回答。
从上面例子可以看出:
(1)不同于传统问答基于数据库或搜索引擎,ChatGPT的答案是在用户输入问题以后,随着问题自动生成的。
(2)这种生成本质上是在做文字接龙,简单来说是不断在所有可能词汇中选择概率最大的词汇来生成。
有些聪明的读者会有一个疑问,ChatGPT是怎么知道该选择什么词汇,又是如何给出各个可能词汇的概率呢?这正是机器学习技术的神奇之处。
机器学习的核心:模仿人类进行学习
ChatGPT是机器学习的一个非常典型的应用,那么什么是机器学习呢?
机器学习整体思想是借鉴人类学习的过程。人类观察、归纳客观世界的实际情况,并从中学到相关的规律,当面对某一未知情况的时候,会使用已经学到的规律来解决未知的问题。同理,我们希望计算机能够自动地从海量数据中发现某种“规律”,并将这种规律应用于一些新的问题。这种规律在机器学习领域就被称为“模型”,学习的过程被称为对模型进行训练。

机器学习和模型训练卡通示意图
关于模型训练,实际上所有机器学习模型背后都有一个假设:学习的规律是能够通过数学表示的。机器学习的核心就是想办法找到一个数学函数,让这个函数尽可能接近真实世界的数学表达式。然而很多时候人类并不知道真实的数学表示是什么形式,也无法通过传统数学推导的方式获得;人类唯一拥有的是一堆来源于真实情境的数据。机器学习的方法就是使用这些数据(训练数据)去训练我们的模型,让模型自动找到一个较好的近似结果。比如人脸识别的应用,就是想找到一个函数,这个函数的输入是人脸照片,输出是判定这张照片对应哪个人。然而人类不知道人脸识别函数是什么形式,于是就拿来一大堆人脸的照片并且标记好每个脸对应的人,交给模型去训练,让模型自动找到一个较好的人脸识别函数。这就是机器学习在做的事情。
神经网络与神经元:可扩展的数学表达能力
理解了机器学习是什么,另一个概念是机器学习模型的数学表达能力。机器学习模型本质上是想要尽可能接近真实世界对应的那个函数。然而正如我们不能指望仅仅通过几条直线就画出精美绝伦的美术作品,如果机器学习模型本身比较简单,比如高中学到的线性函数
Y=kx+b
那么它无论如何也不可能学习出一个复杂的函数。因此机器学习模型的一个重要考虑点就是模型的数学表达能力,当面对一个复杂问题的时候,我们希望模型数学表达能力尽可能强,这样模型才有可能学好。
过去几十年科学家发明了非常多不同的机器学习模型,而其中最具影响力的是一种叫作“神经网络”的模型。神经网络模型最初基于生物学的一个现象:人类神经元的基础架构非常简单,只能做一些基础的信号处理工作,但最终通过大脑能够完成复杂的思考。受此启发,科学家们开始思考是否可以构建一些简单的“神经元”,并通过神经元的连接形成网络,从而产生处理复杂信息的能力。
基于此,神经网络的基础单元是一个神经元的模型,其只能进行简单的计算。假设输入数据有2个维度(x1, x2),那么这个神经网络可以写成
y=σ(w1x1+w2x2+b)
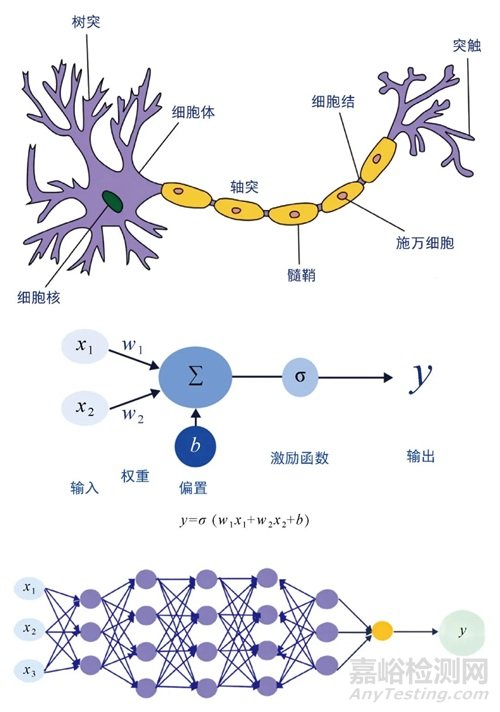
从神经元到神经网络 (a)神经元架构(生物);(b)基础神经元架构(人工智能);(c)简单多层感知机。
上述神经元的数学表达能力非常弱,只是一个简单的线性函数和一个激活函数的组合;但是我们可以很轻松地把模型变得强大起来,方案就是增加更多的“隐藏节点”。在这个时候虽然每个节点依然进行非常简单的计算,但组合起来其数学表达能力就会变得很强。感兴趣的读者可以尝试类比上述公式写出下图中简单多层感知机对应的公式,将会得到一个非常复杂的公式。这个模型也是日后深度学习的基础模型,即多层感知机[1]。
多层感知机的原理非常简单,但是透过它可以很好地了解神经网络的原理:虽然单个神经元非常简单,但是通过大量节点的组合就可以让模型具备非常强大的数学表达能力。而之后整个深度学习的技术路线,某种程度上就是沿着开发并训练更大更深的网络的路线前进的。
深度学习新范式:预训练+微调范式与Scaling Law
深度学习领域从2012年开始蓬勃发展,更大更深且效果更好的模型不断出现。然而随着模型越来越复杂,从头训练模型的成本越来越高。于是有人提出,能否不从头训练,而是在别人训练好的模型基础上训练,从而用更低的成本达到更好的效果呢?
例如,科学家对一个图像分类模型进行拆分,希望研究深度学习模型里的那么多层都学到了什么东西[2]。结果发现,越接近输入层,模型学到的是越基础的信息,比如边、角、纹理等;越接近输出层,模型学到的是越接近高级组合的信息,比如公鸡的形状、船的形状等。不仅仅在图像领域如此,在自然语言、语音等很多领域也存在这个特征。
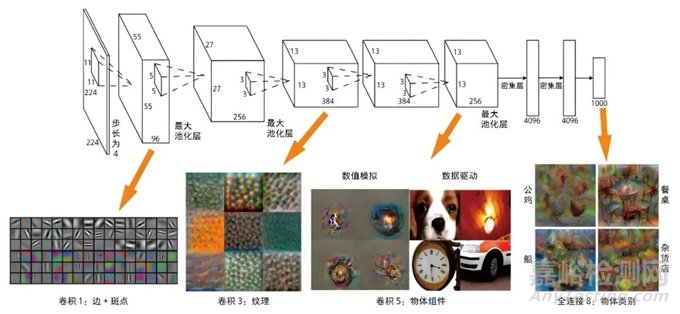
深度神经网络中不同层的输出 接近输入层(左侧)一般是基础信息,接近输出层(右侧)一般是某个具体的物体等信息[2]。
基础信息往往是领域通用的信息,比如图像领域的边、角、纹理等,在各类图像识别中都会用到;而高级组合信息往往是领域专用信息,比如猫的形状只有在动物识别任务中才有用,在人脸识别的任务就没用。因此一个自然而然的逻辑是,通过领域常见数据训练出一个通用的模型,主要是学好领域通用信息;在面对某个具体场景时,只需要使用该场景数据做个小规模训练(微调)就可以了。这就是著名的预训练+微调的范式。
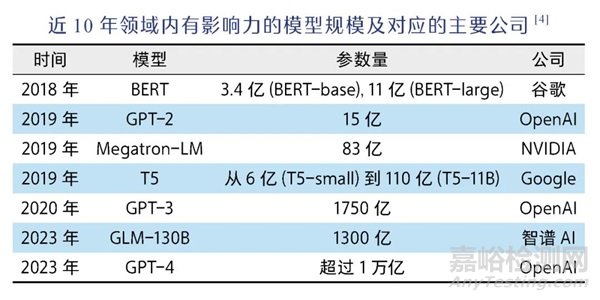
预训练+微调这一范式的出现与普及对领域产生了两个重大影响。一方面,在已有模型基础上微调大大降低了成本;另一方面,一个好的预训练模型的重要性也更加凸显,因此各大公司、科研机构更加愿意花大量成本来训练更加昂贵的基础模型。那么大模型的效果到底与什么因素有关呢?OpenAI在2020年提出了著名的Scaling Law,即当模型规模变大以后,模型的效果主要受到模型参数规模、训练数据规模和使用算力规模影响[3]。
Scaling Law积极的一面是为提升模型效果指明了方向,只要把模型和数据规模做得更大就可以,这也是为什么近年来大模型的规模在以指数级增长,以及基础算力资源图形处理器(graphics processing unit, GPU)总是供不应求;但Scaling Law也揭示了一个让很多科学家绝望的事实:即模型的每一步提升都需要人类用极为夸张的算力和数据成本来“交换”。大模型的成本门槛变得非常之高,从头训练大模型成了学界的奢望,以OpenAI、谷歌、Meta、百度、智谱AI等企业为代表的业界开始发挥引领作用。
GPT的野心:上下文学习与提示词工程
除了希望通过训练规模巨大的模型来提升效果以外,GPT模型在发展过程中还有一个非常雄大的野心:上下文学习(in-context learning)。
正如前文所述,在过去如果想要模型“学”到什么内容,需要用一大堆数据来训练我们的模型;哪怕是前文讲到的预训练+微调的范式,依然需要在已训练好的模型基础上,用一个小批量数据做训练(即微调)。因此在过去,“训练”一直是机器学习中最核心的概念。但OpenAI提出,训练本身既有成本又有门槛,希望模型面对新任务的时候不用额外训练,只需要在对话窗口里给模型一些例子,模型就自动学会了。这种模式就叫作上下文学习。
举一个中英文翻译的例子。过去做中英文翻译,需要使用海量的中英文数据集训练一个机器学习模型;而在上下文学习中,想要完成同样的任务,只需要给模型一些例子,比如告诉模型下面的话:
下面是一些中文翻译成英文的例子:
我爱中国 → I love China
我喜欢写代码 → I love coding
人工智能很重要 → AI is important
现在我有一句中文,请翻译成英文。这句话是:“我今天想吃苹果”。
这时候原本“傻傻的”模型就突然具备了翻译的能力,能够自动翻译了。
有过ChatGPT使用经历的读者会发现,这个输入就是提示词(prompt)。在ChatGPT使用已相当普及的今天,很多人意识不到这件事有多神奇。这就如同找一个没学过英语的孩子,给他看几个中英文翻译的句子,这个孩子就可以流畅地进行中英文翻译了。要知道这个模型可从来没有专门在中英文翻译的数据集上训练过,也就是说模型本身并没有中英文翻译的能力,但它竟然通过对话里的一些例子就突然脱胎换骨“顿悟”了中英文翻译,这真的非常神奇!
上下文学习的相关机制到今天依然是学界讨论的热点,而恰恰因为GPT模型具有上下文学习的能力,一个好的提示词非常重要。提示词工程逐步成为一个热门的领域,甚至出现了一种新的职业叫作“提示词工程师”(prompt engineer),就是通过写出更好的提示词让ChatGPT发挥更大的作用。
ChatGPT原理总结如下:
(1) ChatGPT本质是在做文字接龙的游戏,在游戏中它会根据候选词汇的概率来挑选下一个词。
(2) ChatGPT背后是一个非常庞大的神经网络,比如GPT-3有1700亿个参数(训练成本在100万美元以上)。
(3)基于庞大的神经网络,面对一句话时,模型可以准确给出候选词汇的概率,从而完成文字接龙的操作。
(4)这种有巨大规模进行语言处理的模型,也叫作大语言模型(large language model)。
(5)以GPT为代表的大语言模型具备上下文学习的能力,因此一个好的提示词至关重要。
参考文献:
[1] Rumelhart D E, Hinton E G, Williams R J. Learning representations by back-propagating errors. Nature, 1986, 323(6088): 533–536.
[2] Wei D L, Zhou B L, Torralba A,et al. mNeuron: A matlab plugin to visualize neurons from deep models. (2015)[2024-07-05]. https://donglaiw.github.io/proj/mneuron/index.html.
[3] Kaplan J, McCandlish S, Henighan T, et al. Scaling laws for neural language models. arXiv preprint arXiv: 2001.08361, 2020.
[4] Zhao W X, Zhou K, Li J, et al. A survey of large language models. arXiv preprint arXiv: 2303.18223, 2023.
[5] Boiko D A, MacKnight R, Kline B, et al. Autonomous chemical research with large language models. Nature, 2023, 624(7992): 570-578.

来源:科学杂志1915
关键词: ChatGPT