
嘉峪检测网 2025-05-27 19:10
导读:本文介绍了联发科3纳米TCAM存储器技术。
本文是联发科(MediaTek)存储器电路设计专家Sushil Kumar在2025年第72届国际固态电路会议(ISSCC)SRAM专题会议上发表的题为《A 3nm FinFET 2.2Gsearch/s 0.305fJ/b TCAM with Dynamically Gated Search Lines for Data-Center ASICs》的演讲,阐述了联发科新研发的一款采用3纳米Fin-FET工艺的TCAM存储器,该存储器设计创新性地引入了动态门控搜索线技术,专为数据中心专用集成电路(ASIC)打造。
演讲摘要
数据包分类与转发是数据中心网络(DCN)核心组件(如交换机、路由器)的基础功能,用于高效管理和引导网络流量。数据包分类通过解析包头信息识别流量特征,进而执行访问控制(ACL)、服务质量(QoS)等策略;数据包转发则依据路由表确定数据包的下一跳路径。三态内容寻址存储器(TCAM)通过并行内存搜索将输入数据包头与存储规则进行比对,从而加速这两项任务。TCAM提供的快速并行查找功能,使其成为DCN专用集成电路(ASIC)不可或缺的基础IP核。然而TCAM存在显著能耗代价——全条目并行搜索功耗密集,这将影响网络设备的运行效率、可靠性及环境足迹。为降低DCN-TCAM功耗,联发科设计了一款基于3nm FinFET工艺、支持2.2G次搜索/秒、能效0.305fJ/比特的TCAM,其创新设计包括: (1)动态门控搜索线(DGSL)架构,可实现37.4%的功耗节省与46.6%的峰值电流降低; (2)非对称分割架构(ASA),可带来与位宽相关的额外节电效益。
Outline
数据中心网络专用集成电路(ASIC,Application Specific Integrated Circuit)
网络规则的空间局部性
TCAM(三态内容寻址存储器)结构框图
基准TCAM架构及其挑战
动态门控搜索线(DGSL,Dynamically Gated Search Line)架构
• 动态搜索线(SL)的节能设计
• 峰值电流降低
非对称分割架构(ASA)
与现有技术的对比优势
总结与结论
数据中心网络专用集成电路(ASIC)
组成部分
• 互联网交换机与路由器
核心任务
• 分类(Classification): 基于策略
• 转发(Forwarding): 基于路由表
访问控制列表(ACL)
• 规则集合: 策略/路由表
DCN ASIC 的核心需求
• 高速并行查找
• 大容量规则存储
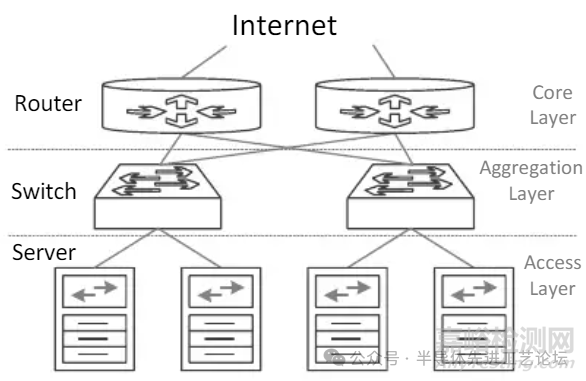
典型数据中心网络架构
TCAM(三态内容寻址存储器): DCN ASIC 的基础IP核
网络规则的空间局部性
规则的相似性与优先级
• 相似规则通常相邻存储: 内容相似的规则倾向于被编程在彼此靠近的位置
TCAM划分为8个存储块(Bank)
• 每个存储块代表不同的优先级层级
匹配规则的空间局部性
• 若某个搜索关键字匹配了特定条目,则后续匹配条目很可能位于其附近。
• 若数据包匹配了存储块 B6 中的规则,则不太可能同时匹配存储块 B0 中的规则。
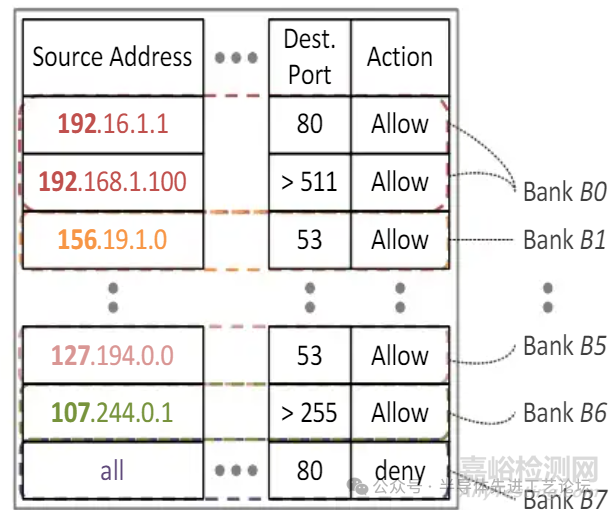
TCAM (三态内容寻址存储器)结构框图
TCAM 结构框图
规格
• 512条目×220位
接口信号
• 控制输入: CK(Clock):时钟信号;SR(Search Enable):搜索使能信号
• 数据输入: SD(Search Data Input): 待搜索数据输入(220 位)
• 输出: HIT(匹配结果): 若SDI与某条目内容匹配则输出高电平,否则输出低电平。
存储块架构
• 512条目均分为8个存储块(Bank),每块含 64 条目。
• 220位SDI拆分为2级匹配宽度(每级110 位)
• 每存储块每级为64条目×110位
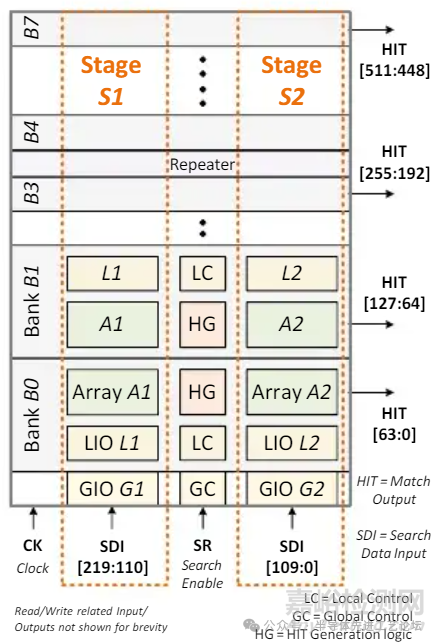
512条目×220位模块框图
TCAM 存储单元
位单元结构
• 两个6T-SRAM单元: 用于存储三态值
• 4T-NMOS堆叠结构: 将搜索关键字(Search Key)与TCAM中的三态值进行比对
功能特性
• 失配(Mismatch):输出下拉至低电平;
匹配(Match):保持高电平
• 读写操作: 与标准6T-SRAM一致
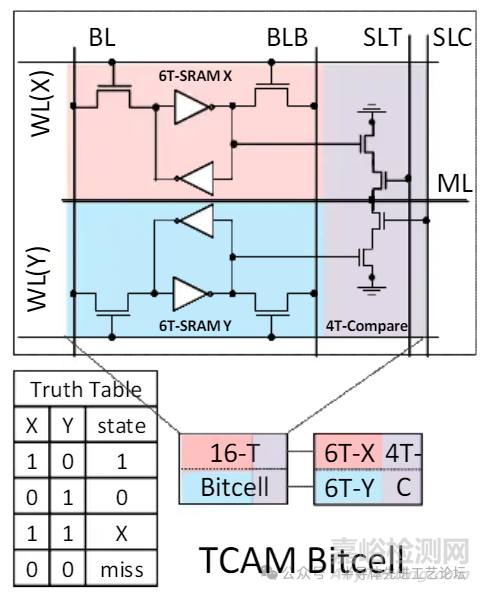
TCAM位单元与真值表
基准 TCAM 架构及其挑战
基准架构
并行阶段S1和S2操作
预比较操作(Pre-compare)
• GIO生成S1_GSLT/C(存储块输入信号)
• LIO提供 S1_SLT/C(比较基准值)
• ML(匹配线)在比较前预充电至高电平
比较操作(Compare Operation)
• SDI与TCAM存储值在ML上进行比对
• S1HIT和S2HIT信号经触发器锁存,生成每个条目的最终匹配输出(HIT)。
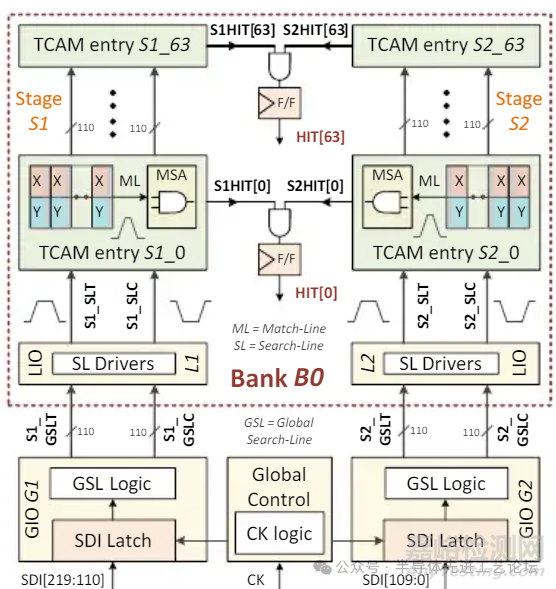
基准TCAM 特性:S1和S2并行工作(两级比较电路同时运行以提升吞吐率)
基准架构
并行阶段S1和S2操作
预比较操作(Pre-compare)
• GIO生成S1_GSLT/C(存储块输入信号)
• LIO提供S1_SLT/C(比较基准值)
• ML(匹配线)在比较前预充电至高电平
比较操作(Compare Operation)
• SDI与TCAM存储值在ML上进行比对
• S1HIT和S2HIT信号经触发器锁存,生成每个条目的最终匹配输出(HIT)。
基准TCAM特性:S1和S2并行工作(两级比较电路同时运行以提升吞吐率)
基准架构
并行阶段S1和S2操作
预比较操作(Pre-compare)
• GIO生成S1_GSLT/C(存储块输入信号)
• LIO提供S1_SLT/C(比较基准值)
• ML(匹配线) 在比较前预充电至高电平
比较操作(Compare Operation)
• SDI与TCAM存储值在ML上进行比对
• S1HIT和S2HIT信号经触发器锁存,生成每个条目的最终匹配输出(HIT)。
基准TCAM特性:S1和S2并行工作(两级比较电路同时运行以提升吞吐率)
挑战: 动态搜索功耗
最坏情况: 全失配(all-miss)
细分项
• 匹配线(ML)35%: 每周期预充电与放电
• 搜索线(SL)37%:每周期根据数据翻转(SLT/C信号切换)
• 其他(28%): GSLT/C切换、控制逻辑、HIT信号等
已提出许多降低匹配线功耗的技术
降低搜索线(SL)功耗难以实现
TCAM功耗分布分析
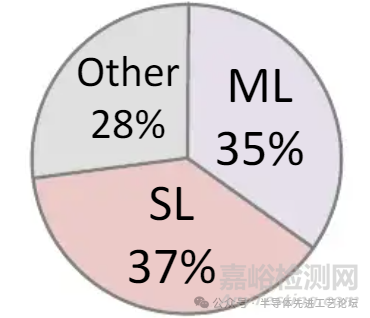
核心挑战:如何降低匹配线(ML)和搜索线(SL)的功耗?
动态门控搜索线(DGSL,Dynamically Gated Search Line)架构
• 动态搜索线(SL)的节能设计
• 峰值电流降低
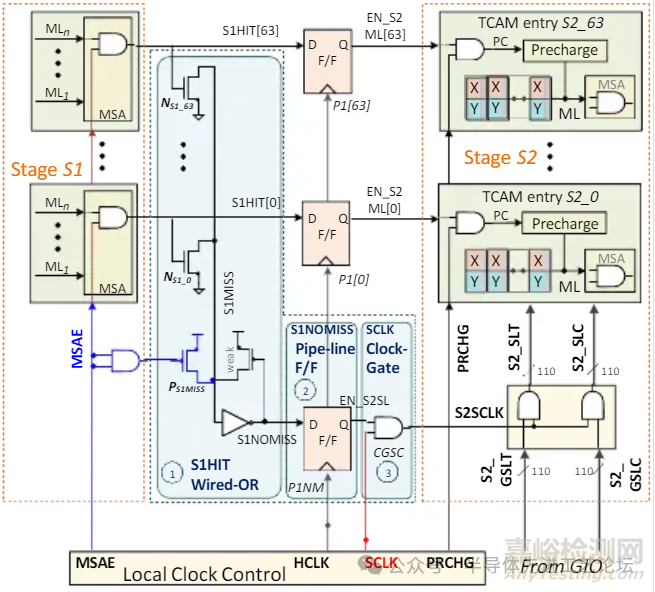
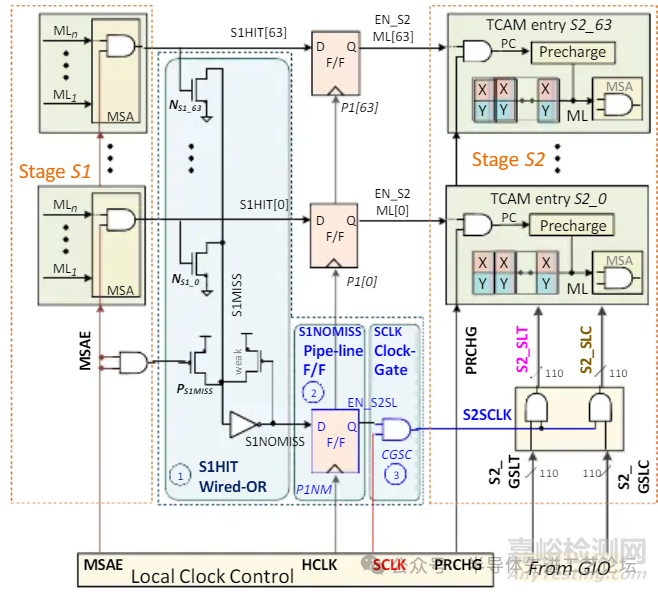
DGSL TCAM 架构
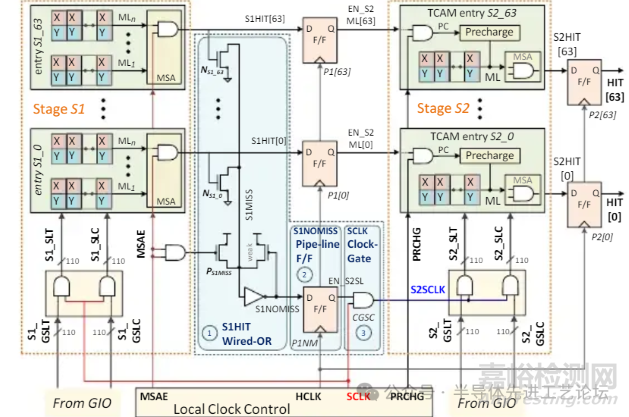
DGSL(动态门控搜索线架构,Dynamically Gated Search-line)
DGSL TCAM 架构详解
S1与S2阶段顺序执行
•3周期延迟
匹配线(ML)节能
搜索线(SL)节能: 依赖三大创新组件
①S1HIT线或(Wired-OR)逻辑电路: 快速识别潜在匹配区域
②S1NOMISS流水线触发器(P1NM):锁存阶段S1的无失配标志
③时钟门控单元(CGSC): 动态关闭未激活区域的时钟信号
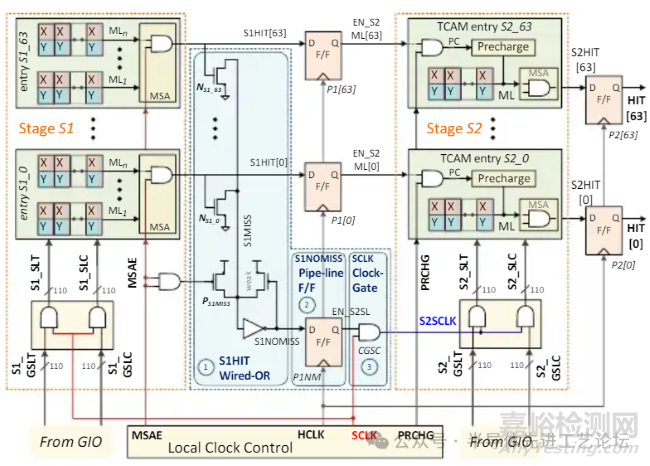
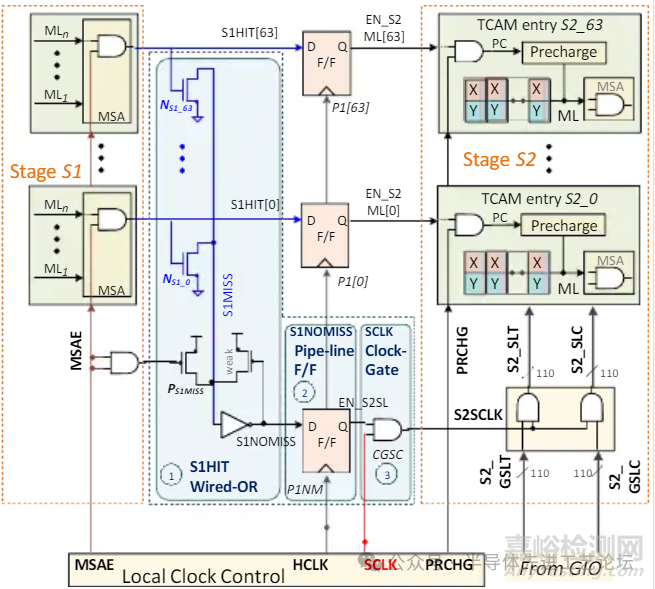
DGSL TCAM 架构详解
S1与S2阶段顺序执行
•3周期延迟
匹配线(ML)节能
搜索线(SL)节能: 依赖三大创新组件
①S1HIT线或(Wired-OR)逻辑电路: 快速识别潜在匹配区域
②S1NOMISS流水线触发器(P1NM):锁存阶段S1的无失配标志
③时钟门控单元(CGSC): 动态关闭未激活区域的时钟信号
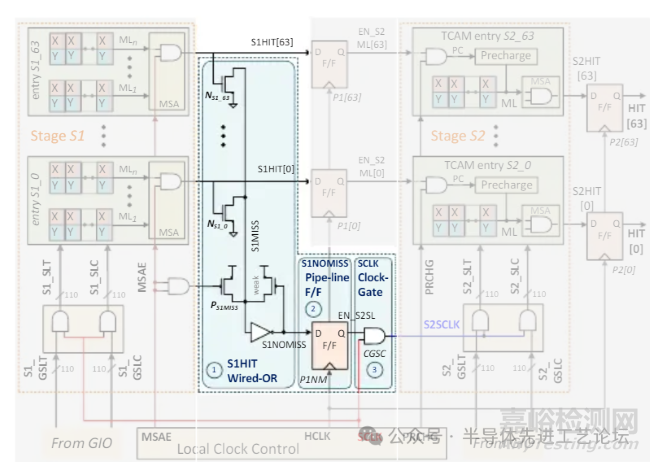
DGSL TCAM 的匹配线(ML)节能机制
阻止S2阶段ML预充电
•当大多数条目失配(miss)时,S1HIT信号基于预比较结果保持为0。
•通过触发器(flopped)锁存的S1HIT信号,关闭S2阶段的ML预充电。
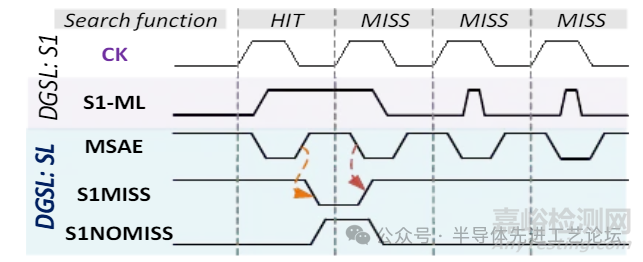
DGSL TCAM-搜索线(SL)节能机制(1/2)
关键组件1: 线或(WIRED OR)逻辑电路
• 当主控信号MSAE=0时,对S1MISS信号线进行预充电。
• 所有一级匹配信号(S1HIT)通过分布式线或结构汇总至S1MISS
• 任一存储块命中(S1HIT=1)→S1MISS立即下拉至0
• 全存储块失配(所有S1HIT=0)→S1MISS维持预充电高电平1
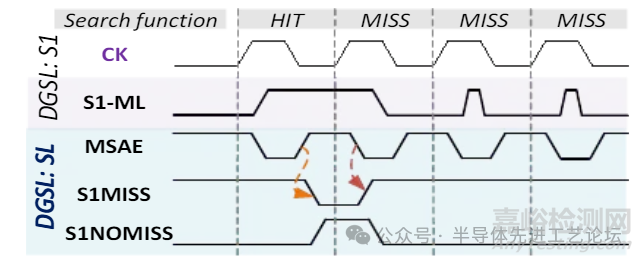
DGSL TCAM-搜索线(SL)节能机制(1/2)
关键组件1:线或(WIRED OR)逻辑电路
•当主控信号MSAE=0时,对S1MISS信号线进行预充电。
•所有一级匹配信号(S1HIT)通过分布式线或结构汇总至S1MISS
•任一存储块命中(S1HIT=1)→S1MISS立即下拉至0
•全存储块失配(所有S1HIT=0)→S1MISS维持预充电高电平1
DGSL TCAM-搜索线(SL)节能机制(2/2)
关键组件2: S1无失配触发器(S1NOMISS F/F)
关键组件3: 时钟门控单元(CGSC)
• EN_S2SL-二级搜索线使能信号
• S2SCLK-门控生成的局部时钟
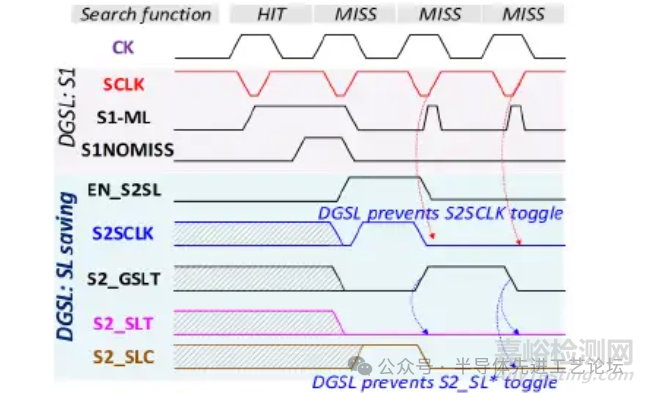
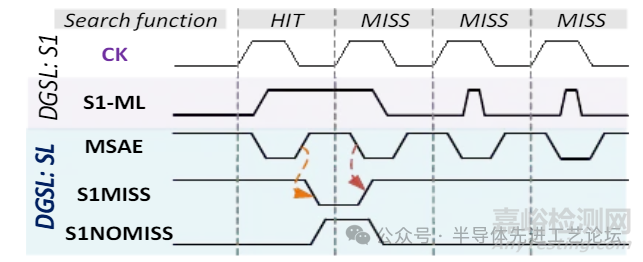
DGSL时序对比分析
基准架构vsDGSL仿真与时序图
• 分布式全局搜索线架构下,S2阶段的SCLK(搜索时钟)与SLT/C(搜索线真值/补码信号)无翻转。

DGSL架构的搜索功耗优化
ML(匹配线)功耗节省: 较基线降低16.7%
DGSL搜索线(SL)功耗节省
•与全未命中存储体数量呈线性节省关系
• 全存储体未命中时总功耗降低37.4%
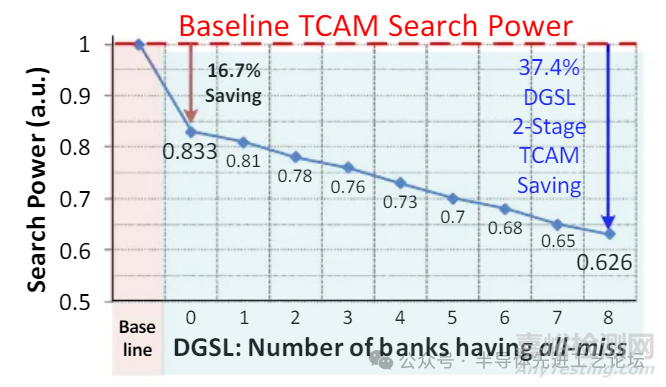
DGSL峰值电流降低与基线对比
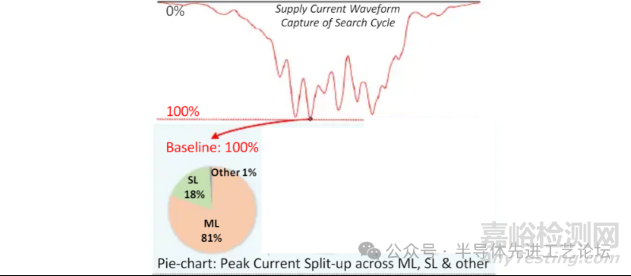
TCAM中的并行搜索:高峰值电流
• IR压降问题
基线峰值主要由ML(机器学习)主导
DGSL峰值电流降低与基线对比
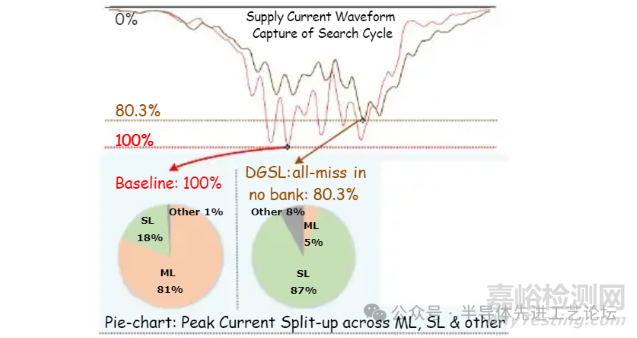
DGSL(全未命中创新存储体): 阻止S2-ML预充电
• 峰值事件转移至SL切换
• 峰值电流降至基准值的80.3%
DGSL峰值电流降低与基线对比
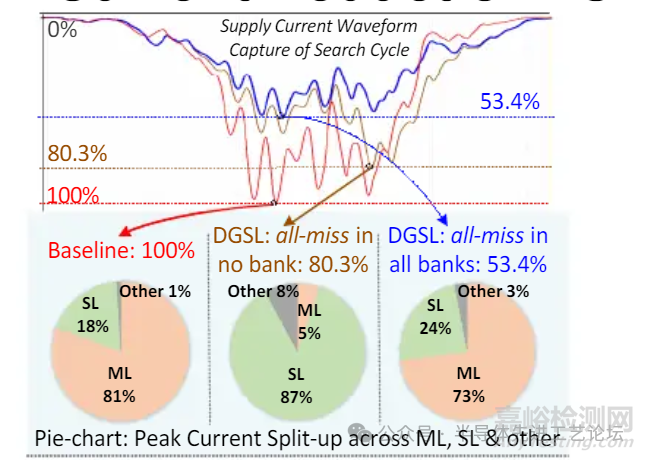
DGSL(全存储体未命中模式): 有效抑制S2_SLT/C信号翻转
• 峰值电流事件回移至ML预充电阶段
• 峰值电流降至基准值的53.4%
非对称分割架构(ASA)
DCN(数据中心网络)可支持最高220位搜索键宽的不同实例配置
• 对于220位实例,110位分别分配至第1和第2阶段。

能否通过对较小10位宽实例采用位分割技术来降低功耗?
非对称分割架构(ASA)
164位分割方案
• 对称分割: 每阶段82位
• 非对称分割: 第一阶段54位,第二阶段110位。
非对称分割架构(ASA)
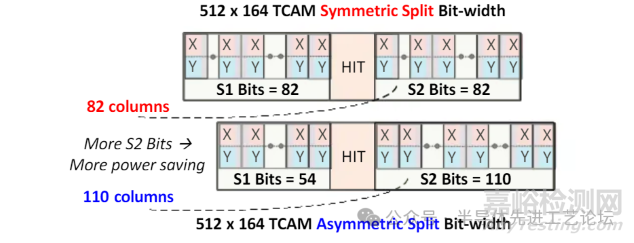
164位分割方案
• 对称分割: 每阶段82位
• 非对称分割: 第一阶段54位,第二阶段110位。
在S1阶段进行预比较可节省ML与SL功耗
采用ASA架构的节能效果
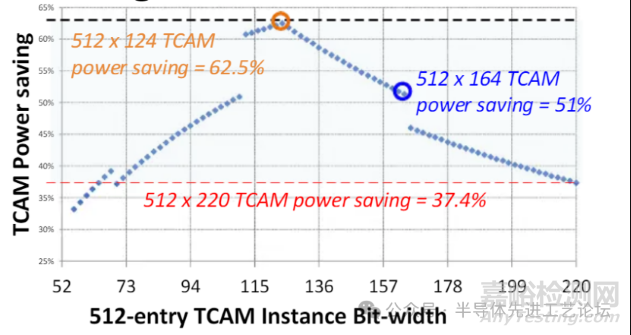
512×164配置可节省51%的搜索功耗
512×124实例实现最高节能效率达62.5%
与现有技术的对比优势
总结与结论
与现有技术的对比优势
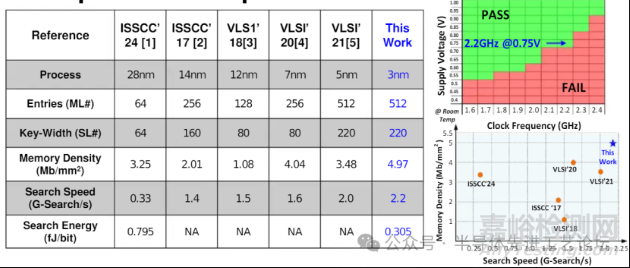
实现了最高频率和最大存储密度
芯片照片与性能总结表
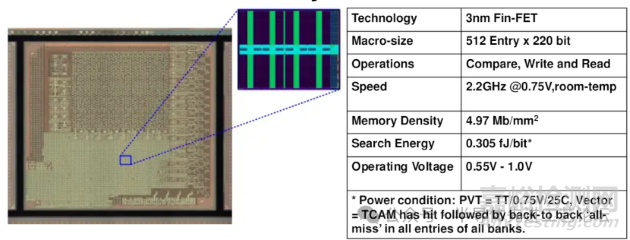
结论
本文提出一款512条目×220位搜索位的动态门控搜索线(DGSL)TCAM存储器。
相较于基准架构,该设计实现了37.4%的功耗降低,搜索能耗达0.305飞焦/比特(fJ/b)。
该宏单元(Macro)实现了业界最高的2.2 GHz工作频率。
该设计实现46.6%的峰值电流降低。
该宏单元(Macro)实现业界最高存储密度:4.97Mb/mm²。
针对10位窄位宽实例的非对称分割架构(ASA)实现方案。
3nm FinFET工艺硅验证结果

来源:半导体先进工艺论坛
关键词: 存储器