
嘉峪检测网 2025-07-25 22:14
导读:本文是台积电(TSMC)存储器IP开发总监Tsung-Yung Jonathan Chang博士在2025年第72届国际固态电路会议(ISSCC)SRAM专题会议上发表的题为《A 38.1Mb/mm2 SRAM in a 2nm-CMOS-Nanosheet Technology for High-Density and Energy-Efficient Compute》的演讲。
本文是台积电(TSMC)存储器IP开发总监Tsung-Yung Jonathan Chang博士在2025年第72届国际固态电路会议(ISSCC)SRAM专题会议上发表的题为《A 38.1Mb/mm2 SRAM in a 2nm-CMOS-Nanosheet Technology for High-Density and Energy-Efficient Compute》的演讲。
英特尔与台积电关于先进制程节点中的相同SRAM面积微缩成果对比在上篇公众号发文中我们详细阐述了英特尔基于18A工艺节点RibbonFET与PowerVia技术的高容量(HCC)/高密度(HDC)6T SRAM架构:相较FinFET方案,HCC与HDC存储单元面积分别缩减至0.77倍与0.88倍,对应0.023μm²与0.021μm²。通过优化传输门(PG)与下拉管(PD)比例,可在读写路径间实现最低VMIN。RibbonFET技术使HDC/HCC存储单元无需依赖字线欠压驱动(WLUD)等辅助电路即可达成具有竞争优势的VMIN,并在全压驱动下获得额外读取性能增益。台积电在2025年ISSCC SRAM专题会议中详述其2nm(N2)节点的SRAM微缩路线。SRAM微缩在3nm节点停滞之后,于2nm节点实现部分重启。台积电基于2nm的SRAM宏单元采用0.021μm²存储单元,阵列规模为4096×145(总容量580Kb)。相较前代节点,存储密度提升10%,达到38.1Mb/mm²。为实现这一目标,台积电通过最大化存储单元阵列规模并最小化外围电路:2nm纳米片晶体管技术改善了存储单元的开关电流比,使得单条位线(BL)可负载的单元数量翻倍。相较于FinFET技术最大256单元/BL的限制,2nm技术允许其扩展至512单元/BL。此外,采用飞行位线(FBL)架构进一步提升了阵列效率。这本质上是利用纳米片晶体管(NSH)较FinFET更优的Ion/Ioff特性,重构外围电路设计。综上所述,尽管技术路径不同(纳米片vs纳米带),台积电N2与英特尔18A均实现SRAM存储单元0.021μm²级密度。从单纯追求特征尺寸微缩,转向器件结构创新(GAA)与系统级供电/互连优化(PowerVia/FBL)的协同设计。新型晶体管通过Ion/Ioff提升,推动存储阵列规模扩展与外围电路精简,为存算一体架构奠定物理基础。
演讲摘要在本文中,台积电(TSMC)提出了一种基于2nm CMOS纳米片工艺的38.1Mb/mm² 高密度SRAM设计,用于高密度与高能效计算应用。该设计采用0.021um²的高密度存储单元,并通过设计-工艺协同优化(DTCO),使整体SRAM密度较前代技术节点提升1.1倍。
嵌入式存储器是片上系统(SoC)设计的关键组成部分,其中静态随机存取存储器(SRAM)在提升各类应用场景的系统性能中发挥着核心作用。随着技术节点的演进,对高容量片上SRAM的持续需求推动着存储密度的极限优化。在成熟技术节点中,缩小存储单元面积曾是实现SRAM微缩的主要途径;然而,随着技术进入更先进节点,单纯依赖单元面积微缩的难度显著增加。此时,设计-工艺协同优化(DTCO)成为芯片层级进一步缩减面积的关键手段。我们通过同步优化单元及外围电路设计以提高存储密度。同时,我们的SRAM设计充分利用了2nm纳米片技术的独特优势。通过探索SRAM宏架构、设计辅助技术和版图规划等多个设计维度的创新,实现了存储阵列性能的全面提升。本方案的核心设计目标是在最小化外围电路面积的同时最大化存储阵列占比:基于2nm纳米片晶体管优异的开关电流比(Ion/Ioff),将单条位线(BL)驱动单元数量提升至前代技术的2倍,最大位线负载能力实现倍数级提升,直接扩大有效存储阵列规模。此外,我们针对外围逻辑电路实施了三项特殊设计规则(详见图29.1.1(a)),实现面积效率的突破性优化。
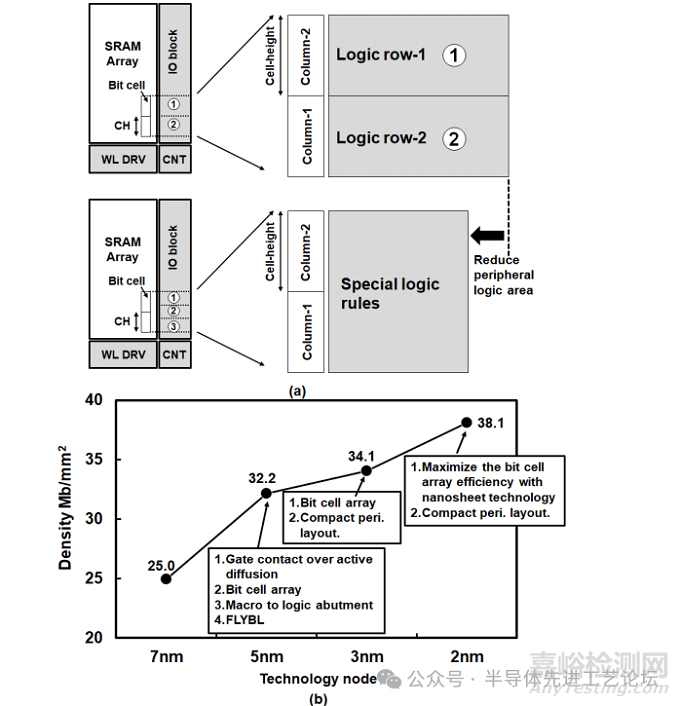
图29.1.1:(a)采用特殊逻辑规则实现外围逻辑电路面积缩减;(b)高密度SRAM位密度技术演进趋势
为提升存储密度,本文提出一种基于2nm纳米片技术的高密度(HD)SRAM设计方案。该SRAM宏单元采用0.021um²存储单元,总容量达580kb(4096×145)。通过设计-工艺协同优化(DTCO),其整体密度较前代技术节点提升10%,实现38.1Mb/mm²的存储密度(见图29.1.1(b))。为降低最小写入电压(VMIN),设计中集成负位线(NBL)写入辅助技术[1-5]。
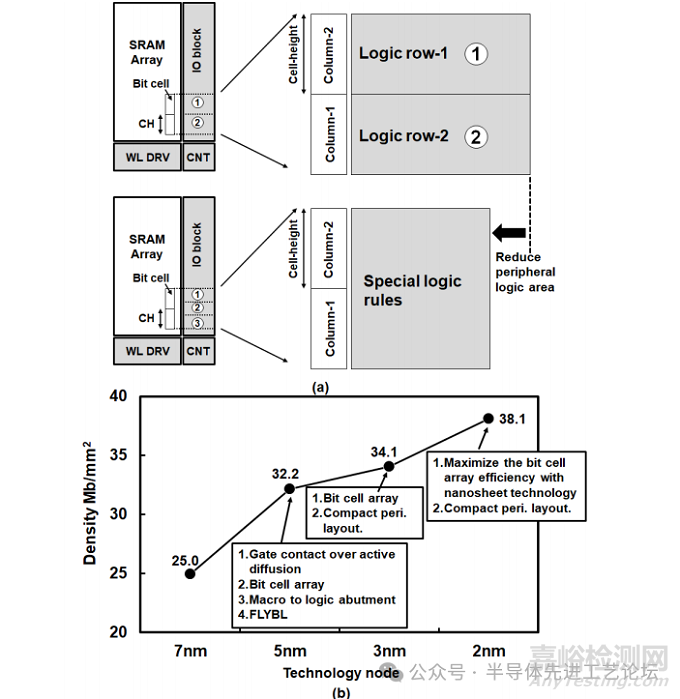
图29.1.1:(a)采用特殊逻辑规则实现外围逻辑电路面积缩减;(b)高密度SRAM位密度技术演进趋势图
29.1.2(a)展示了采用FinFET技术的传统SRAM宏设计架构。在该设计中:受限于FinFET器件的电流驱动能力,每条位线(BL)最多驱动256个单元。相比之下,2nm纳米片技术凭借存储单元开关电流比(Ion/Ioff)的大幅提升,成功将单条位线(BL)驱动单元数量增至512个,使SRAM宏单元的存储效率获得显著提升。此外,通过将位线(BL)容量增加到512个存储单元,并采用飞行位线(FBL)架构,阵列效率得到了提升。图29.1.2(b)展示了飞行位线(FBL)宏单元架构,其上下存储区均有512行存储单元,上存储区位线(BL)通过下存储区上方的悬空位线第二层金属(FBL metal 2)连接到主输入输出(MIO)模块,形成1024伪行架构,相较传统FBL架构(仅支持256行)实现容量倍增。
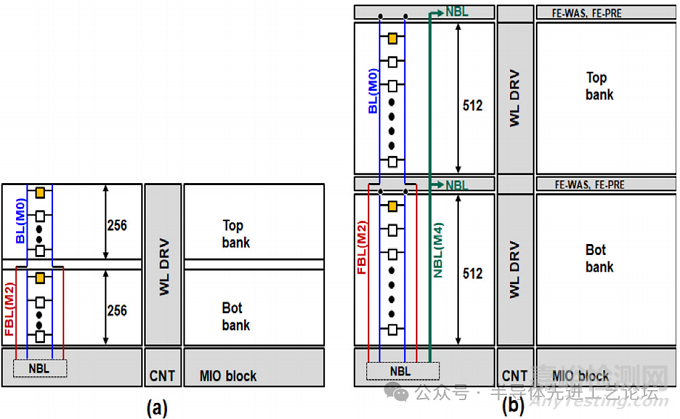
图29.1.2:(a)典型FinFET SRAM宏架构;(b)采用512行上下存储区的飞行位线(FBL)宏架构
然而,随着单条位线(BL)驱动单元数量的增加以及底层存储区飞行位线(FBL)架构的引入,会导致顶层与底层存储区的BL电阻和电容增大。由于位线(BL)电阻/电容显著增加,实现1024伪行架构(每条位线驱动512单元+FBL层叠加512单元)时存在以下三个关键技术挑战:(1)由于BL电阻升高导致远端负位线(NBL)电压损失加剧;2)位线升压电容需求增加;(3)BL预充电时间延长;为了应对这些挑战,本文创新性地提出将写入辅助模块(WAU)与位线预充电电路(BPCU)分布式布局于存储阵列远端。该优化设计提高了远端存储单元的可写入性和预充电能力。
图29.1.3(a)展示了所提出的远端写入辅助(FE-WA)与远端预充电(FE-PRE)方案,旨在将每条位线(BL)驱动单元数扩展至512个。为缓解远端单元写入性能劣化,FE-WA与FE-PRE模块分别置于上下存储区的顶端。上存储区BL通过金属2层(FBL)跨越下存储区,连接至主输入输出(MIO)模块;MIO的写入驱动器采用负位线(NBL)技术实现写入辅助。传统设计中,负位线(NBL)升压电容通常采用MOS电容结构,通过耦合效应产生带负偏压(NVSS)的电压。升压电容集成于主I/O模块(MIO)内部,生成的NBL偏压信号需穿越底层存储区金属布线,最终传输至顶层和底层存储区的远端写入辅助模块(FE-WA)。
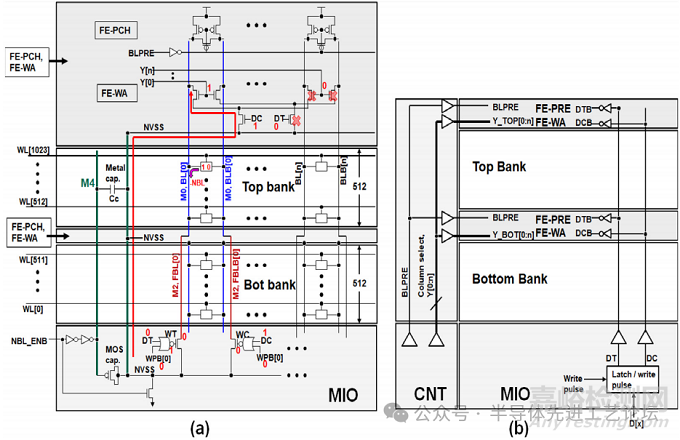
图29.1.3:(a)所提出的远端写入辅助(FE-WA)与远端预充电(FE-PRE)方案,支持单条位线(BL)驱动512个存储单元;(b)控制FE-WA与FE-PRE模块的全局信号框图。金属4层(M4)布线作为金属耦合电容介质,将负偏压(NVSS)传输至远端写入辅助模块(FE-WA)。在远端写入辅助(FE-WA)模块中,DT和DC控制一对NMOS写入驱动器,源极连接NVSS以向单元注入负偏压。串联在写入驱动器漏极的另一对NMOS作为列复用选择器,这对NMOS晶体管的栅极由列地址(Y[0], …, Y[n])控制,实现目标列的写入使能。当写入“0”时,MIO模块中的写入驱动器受DT=0和DC=1及WPB选通信号触发,开始拉低位线 BL [0] 的电位;远端写入辅助(FE-WA)模块同步响应DT=0与DC=1,协助远端BL[0]放电至目标负压。接下来,NBL_ENB信号激活MOS电容与金属4层电容进行耦合,产生负偏压信号NVSS,随后NVSS通过NMOS写入驱动器对向选定BL的近端与远端传输。写入操作完成后,位线(BL)会被预充电至电源电压(VDD),从而结束写入周期。为了缩短写入周期,远端预充电(FE-PRE)模块配备了一对 PMOS预充电和均衡晶体管,用于协助将位线(BL)的电位恢复至电源电压(VDD)。图29.1.3(b)展示了控制远端写入辅助(FE-WA)模块与远端预充电(FE-PRE)模块的全局信号架构图,为了激活远端写入辅助(FE-WA)模块,列选通信号(Y[0:n])通过金属4层(M4)从控制模块(CNT)传输至远端写入辅助(FE-WA)模块,同时利用局部缓冲器来辅助信号重构。此外,写入数据信号(DT和 DC),也就是锁存的待写入数据信号,同样通过金属4层(M4)走线穿过阵列传输至远端写入辅助(FE-WA)模块。远端预充电(FE-PRE)模块由位线预充电信号(BLPRE)激活,该信号也通过金属4层(M4)走线传输至远端预充电(FE-PRE)模块。
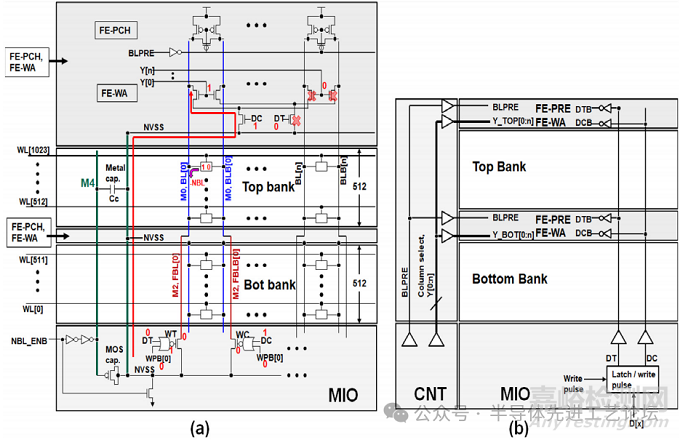
图29.1.3:(a)所提出的远端写入辅助(FE-WA)与远端预充电(FE-PRE)方案,支持单条位线(BL)驱动512个存储单元;(b)控制FE-WA与FE-PRE模块的全局信号框图。
图29.1.4(a)展示了禁用远端写入辅助(FE-WA)与远端预充电(FE-PRE)模块时的仿真波形。由于高位线时间常数(BL time constant)的存在,当仅激活近端负位线(NBL)时,远端位线(BL)无法达到所需的NBL电压,导致远端单元发生写入失败。此外,高BL时间常数会延长BL恢复至VDD的预充电时间。相比之下,图29.1.4(b)则呈现了启用FE-WA与FE-PRE模块后的仿真波形:负位线(NBL)偏置信号能够传输到远端存储单元;因此,这些存储单元能够达到成功写入操作所需的负位线(NBL)电压。此外,FE-PRE模块的启用使BL复位至VDD的速度提升约2倍,大幅缩短预充电时间。
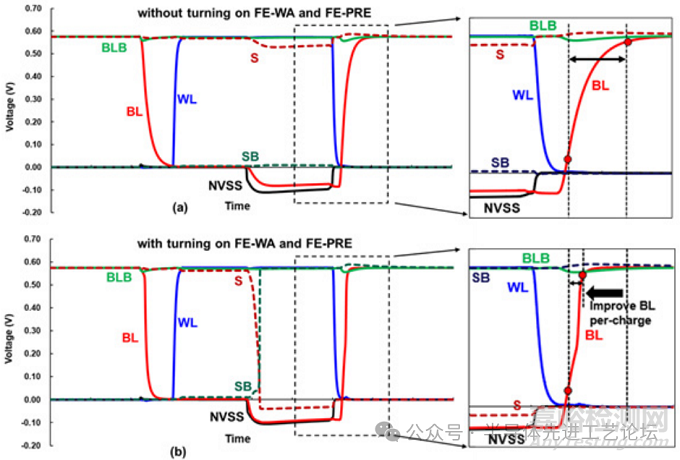
图29.1.4:(a)FE-WA与FE-PRE模块禁用时的仿真波形;(b)FE-WA与FE-PRE模块启用时的仿真波形。
除高密度SRAM外,采用高容量单元(HC Cell)的双泵式SRAM(Double-Pumped SRAM)同样是支撑高性能计算(HPC)应用的关键技术。为提升能效表现,本设计采用图29.1.5所示的双轨追踪方案(Dual-Tracking Scheme),以降低动态功耗并提升速度。在低电压(VDD)工作模式下,该追踪方案通过动态调节确保SRAM在最小工作电压(VMIN)下仍保持足够的读取裕量(RM);而在标称电压范围内,设计自动切换至TURBO模式——绕过追踪电路并启用纯逻辑延迟路径,从而最大化运行频率。这种TURBO模式切换可提高最大工作频率(fMAX),并避免在额定电源电压(VDD)下运行时出现过大的读取裕量(RM)。相较3nm工艺同类设计,所提出的双跟踪方案使双泵式SRAM的速度提升了6.3%,动态功耗降低了11.5%,从而使能源效率提高了20%。
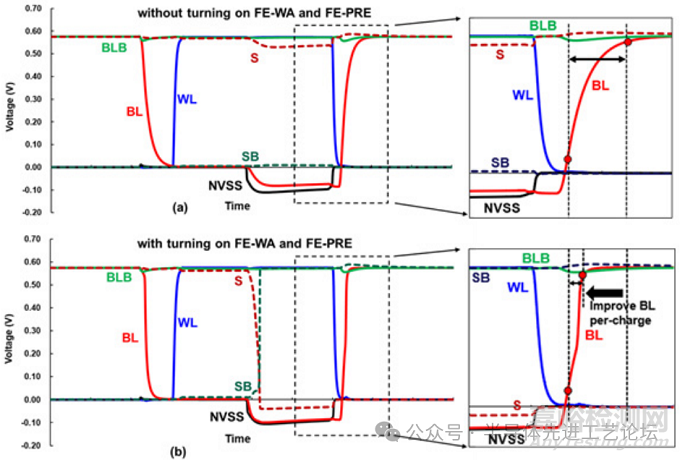
图29.1.5:双泵式SRAM(Double-Pumped SRAM)的双轨追踪方案(Dual-Tracking Scheme)
图29.1.6(a)展示了2Mb高密度(HD)SRAM硅测试芯片在25℃下的最小工作电压(VMIN)测试结果:集成4个580kb SRAM宏单元,这些宏单元被配置为4096×145的四路复用(mux-4)结构,且每条位线(BL)上有伪1024个存储单元。
图29.1.6(b)展示了256Mb高密度SRAM在25℃下的最小工作电压(VMIN)性能,由2048个SRAM宏单元构成,这些宏单元被配置为4096×32 的十六路复用(mux-16)结构,且每条位线(BL)上有256个存储单元。与未使用写入辅助技术的情况相比,应用写入辅助技术使2Mb和256Mb的SRAM在95%分位处的最小工作电压(VMIN)均降低了300mV。图29.1.6(c)展示了双泵式32kb SRAM在25℃下,配置为 512×64的四路复用(mux-4)结构的频率-电压测试结果(Shmoo 图)。所提出的双跟踪方案使得该SRAM在1.05V电源电压下能够实现4.2GHz的最大工作频率(fMAX)。
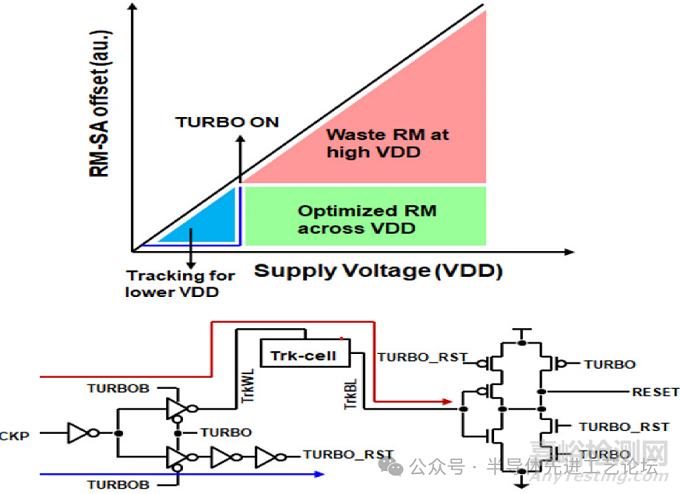
图29.1.6:(a)基于1024伪单元架构的2Mb高密度SRAM(HD-SRAM)在25℃下的最小工作电压(VMIN)的硅测试结果。传统256单元/位线(cells/BL)架构的256Mb HD-SRAM VMIN累积分布图;(c)双泵式SRAM的频率/电压测试结果(Shmoo图)。
图29.1.7展示了SRAM测试芯片及其核心参数摘要。其中一款测试芯片集成了4个580kb SRAM宏单元(配置为每条位线1024个伪存储单元),其特点是采用了远端写入辅助和预充电方案,用于芯片制造完成后的硅后调试,该测试芯片的总容量为2Mb。另一块测试芯片包含2048个SRAM宏单元,每个宏单元的容量为128kb(配置为每条位线256个存储单元),其总容量为256Mb, 该测试芯片集成冗余设计(redundancy)与可编程写入辅助选项,可提升良率与可靠性。此外,两款测试芯片均采用2nm CMOS纳米片工艺制造。
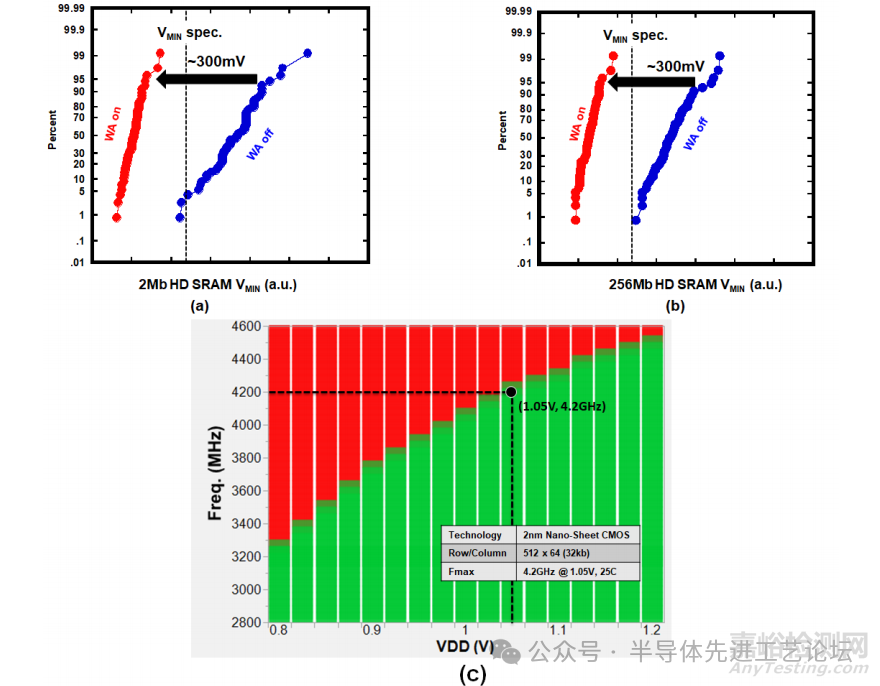
图29.1.7:测试芯片显微照片与关键指标汇总表
致谢作者谨此感谢研发团队为本研究提供的晶圆制造支持,以及测试部门完成的芯片测试工作。

参考文献
[1] J. Chang et al., “A 3nm 256Mb SRAM in FinFET Technology with New Array Banking Architecture and Write-Assist Circuitry Scheme for High-Density and Low-VMIN Applications”, IEEE VLSI Symp., 2023.
[2] J. Chang et al., “A 5nm 135Mb SRAM in EUV and High-Mobility-Channel FinFET Technology with Metal Coupling and Charge-Sharing Write-Assist Circuitry Schemes for High Density and Low-VMIN Applications,” ISSCC, pp. 238-239, 2020.
[3] J. Chang et al., “A 7nm 256Mb SRAM in High-K Metal-Gate FinFET Technology with Write-Assist Circuitry for Low-VMIN Applications”, ISSCC, pp. 206-207, 2017.
[4] T. Song et al., “A 7nm FinFET SRAM using EUV lithography with dual write-driver assist circuitry for low-voltage applications”, ISSCC, pp. 198-200, 2018.
[5] Y. Kim et al., “Energy-Efficient High Bandwidth 6T SRAM Design on Intel 4 CMOS Technology”, IEEE VLSI Symp., pp. 212-213, 2022.


来源:Internet