
嘉峪检测网 2025-04-17 15:16
导读:在本论文中,英特尔展示了其采用18A RibbonFET CMOS技术的SRAM设计,该设计运用了PowerVia技术进行背面供电,使用0.023μm²大电流(HCC)与0.021μm²高密度(HDC)存储单元。
本文是英特尔公司先进设计部门的Xiaofei Wang博士在2025年第72届国际固态电路会议(ISSCC)SRAM专题会议上发表的题为《A 0.021μm2 High-Density SRAM in Intel-18A-RibbonFET Technology with PowerVia-Backside Power Delivery》的演讲。
ISSCC 2025 SRAM专题聚焦
SRAM在持续追求更高计算性能的进程中始终发挥着不可替代的作用。随着传统晶体管微缩进程放缓,为实现更高能效计算,亟需通过创新与设计-工艺协同优化(DTCO)进一步突破SRAM的密度、速度与功能边界。本专题聚焦四篇SRAM论文及一篇TCAM(三态内容寻址存储器)论文,这些研究通过架构与电路创新,结合先进工艺技术(包括FinFET、纳米片及背面互连RibbonFET CMOS)中的SRAM存储单元设计,共同推进存储器的密度、速度、功耗与操作极限。
演讲摘要
在本论文中,英特尔展示了其采用18A RibbonFET CMOS技术的SRAM设计,该设计运用了PowerVia技术进行背面供电,使用0.023μm²大电流(HCC)与0.021μm²高密度(HDC)存储单元。与先前的FinFET技术相比,全包围栅(GAA)技术在34.3 Mb/mm²高密度SRAM设计中显示最低工作电压(VMIN)降低68mV,并支持高达38.1 Mb/mm²的面积密度。
对高性能和高能效计算的加速追求推动了最近在先进工艺技术中的半导体器件和功率传输方案的突破。本文介绍了业界首个经过硅验证的量产 采用RibbonFET技术实现的大电流(HCC)和高密度(HDC)6T SRAM,并在外围电路中采用PowerVia技术实现了背面供电传输。RibbonFET技术兼具更优的每瓦性能与密度提升,同时支持灵活调节晶体管有效宽度,以实现SRAM晶体管在功耗、性能及最低工作电压(VMIN)上的最优化设计。PowerVia技术[1-3]通过在晶圆背面构建低阻金属层实现供电,有效降低电压降,并释放正面互连层的信号布线资源,以实现更有效的外围电路设计。与采用FinFET的同类设计[3、4]相比,本文所提出的RibbonFET SRAM设计实现了HCC和HDC的0.77 倍和0.88倍存储单元面积微缩。RibbonFET HCC的测量结果表明,与之前需要读写辅助电路的基于FinFET的设计相比,在不使用辅助电路的情况下,其90%分位的VMIN得到了改善。与此同时,采用负位线(NBL)写入辅助技术的34.3Mb/mm² HDC阵列,其VMIN较前代设计降低68mV。通过更大规模的位阵列配置与外围电路压缩,HDC SRAM的密度可进一步提升至38.1Mb/mm²。
图29.2.1(上图)展示了平面型晶体管、FinFET与RibbonFET的横截面结构示意图。RibbonFET晶体管采用水平堆叠的纳米带状沟道结构,其栅极材料从四个方向完全包覆沟道。相较于FinFET(三面包栅)和平面型晶体管(单面包栅),RibbonFET的四面包覆栅极控制结构具有更优的每瓦性能与更低的晶体管性能波动。同时,RibbonFET凭借更高的宽度/面积比实现更高密度:特别是对于多鳍晶体管,例如HCC NMOS,水平纳米带替代垂直鳍片可消除鳍片间距限制,从而实现了显著的面积微缩。如图 29.2.1(下图)所示,与基于FinFET的设计[3,4]相比,本研究实现的SRAM存储单元面积分别为HCC 0.023μm²与HDC 0.021μm²,面积缩减至0.77倍和0.88倍。
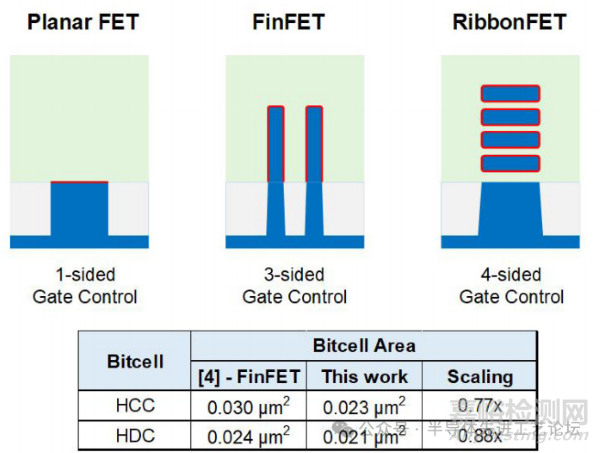
图29.2.1:平面型晶体管、FinFET与RibbonFET结构对比(上图)及FinFET与RibbonFET SRAM存储单元面积对比(下图)
FinFET晶体管的宽度呈离散化特征,由鳍片数量决定;而RibbonFET的有效宽度则与纳米带的制造宽度相关,可实现连续调节。在RibbonFET 6T存储单元中,上拉(PU)、传输门(PG)及下拉(PD)晶体管的宽度可任意设定(类似平面晶体管),而FinFET因离散化限制必须固定器件尺寸比例(例如HCC设计中PU:PG:PD=1:2:2)。此外,通过纳米带拐折(ribbon jog)技术,相邻晶体管间的纳米带宽度可进行差异化调整,从而允许PG与PD晶体管采用不同尺寸[5]。这为优化SRAM存储单元以降低最低工作电压(VMIN)提供了关键调控手段——降低PG:PD比例可提升读取静态噪声容限(SNM),但会恶化写入容限;如图29.2.2(下图)仿真所示,最佳PG:PD比例能实现读取与写入路径间的最低VMIN。RibbonFET技术使得HDC和HCC存储单元都可以设计成具有竞争力的VMIN,无需依赖字线欠压驱动( wordline underdrive,WLUD )读取辅助技术,进而在字线全压驱动下实现更优的读取性能。
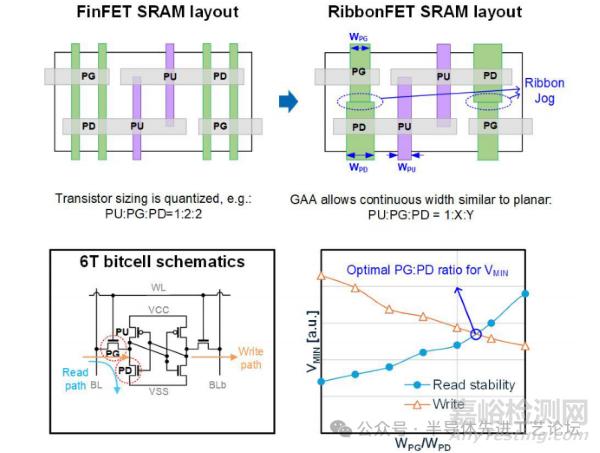
图29.2.2:基于FinFET与RibbonFET的SRAM存储单元版图对比(上图)及RibbonFET非离散化宽度支持在读取稳定性与写入容限间实现VMIN优化(下图)。
图29.2.3(上图)对比展示了传统正面供电网络(FS-PDN)与本研究的背面供电网络(BS-PDN)架构。FS-PDN方案中,电源与信号均布设在晶圆正面金属层;而采用PowerVia的BS-PDN方案则通过背面低阻金属堆叠供电,同时缓解正面金属层的布线拥塞与金属间距限制。在内存存储单元中集成VSS或VCC PowerVias都会导致存储单元面积显著增加;为此,与将PowerVia放置在存储单元阵列内部不同,本研究提出将PowerVia布设于存储单元阵列边界的非活跃过渡区域,并通过正面电源网格向阵列内供电,从而规避上述问题(见图29.2.3下图)。
在本研究所提出的供电方案中,最坏情况下的VSS IR压降出现在存储阵列中心(即距离PowerVia最远的位置)。相较于传统FS-PDN通过通孔在阵列内均匀分布VSS的方案,静态IR仿真表明,所提出的电源方案的最坏情况电阻比阵列中心的VSS R高49%。然而,由于位线(BL)电阻的有效性降低及字线(WL)延迟较小,中心单元(具有最大VSS R)的读取延迟仅为角落单元的约95%。位于阵列角落的最坏读取延迟单元,其VSS R较传统方案仅增加9%。基于PowerVia设计的128字线/WL与256位线/BL架构,仿真结果表明:当电源网格构建至M4金属层时,最坏情况单元的总体延迟较传统FS-PDN方案仅劣化约1%(汇总数据见图29.2.3下图)。

图29.2.3:正面供电网络(FS-PDN)与背面供电网络(BS-PDN)架构对比示意图(上图)及采用阵列外围集成PowerVia技术的存储宏单元供电网络(下图)。
本研究为HDC阵列设计了负位线(NBL)写入辅助技术[6,7],以进一步优化其最低工作电压(VMIN)。如图29.2.4所示,NBL电路经优化可高效生成所需负压电平:写入操作启动时,NMOS管N1使NBLVSS与解码器虚地节点(DECVSS)电位均衡,同时N0将两者接地;随后NBLPULSE信号关断N0,通过大耦合电容(NBL Cap)将NBLVSS耦合至负电压。NBLVSS作为写入驱动器与列复用器组合电路(Write DR+Mux)的虚拟接地节点,选中的列(4选1)位线(BL)或反相位线(BLb)通过NMOS管N3或N4下拉至NBLVSS。非写入状态下,NBLVSS不被驱动以降低漏电,同时WRENb信号控制的NMOS管N2将DECVSS拉至VSS电平,从而禁用所有列复用器。通过集成写入驱动器与列复用器,使NBLVSS仅需单级NMOS晶体管(N3/N4)即可驱动至BL/BLb。
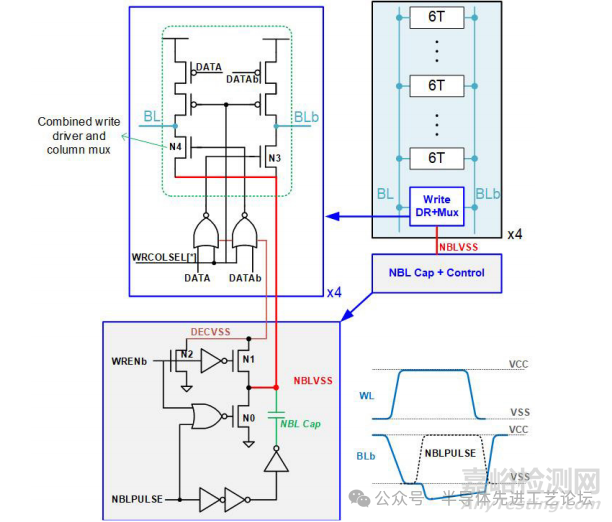
图29.2.4:集成式写入驱动器与列复用器的NBL设计架构,通过减少虚拟NBLVSS节点至BL/BLb间的NMOS堆叠级数,优化NBL电压传输效率。
如图29.2.5(上图)所示,NBL耦合电容可利用阵列下方未部署PowerVia的闲置背面金属走线构建。在256b/BL的HDC阵列下,梳状背面金属电容可以产生类似于MOS电容所能产生的NBL电压,其大小为列IO区域面积的12.8%。除了面积缩减外,背面金属电容随阵列尺寸自然地伸缩,使其能够自动补偿具有较长BL的阵列的写入能力衰减[7]。在存储单元和列IO区域上方的正面金属层(如M4和M5)虽也可用作NBL电容,但它们可能会引起信号拥塞和/或面积开销,这都取决于宏级信号分配和金属轨道可用性。图29.2.5(下图)展示了不同阵列配置下HDC宏单元的存储密度:采用512b/BL与272b/WL的HDC宏单元密度达38.1Mb/mm²;而实测采用的2048×64m4 HDC宏单元(256b/BL+136b/WL)密度为34.3Mb/mm²。相较于文献[4],2048×64m4 HCC宏单元面积缩减至0.74倍,其中外围电路压缩(如测试点移除、正面布线松弛、标准单元高度降低及列IO电路优化)贡献3%面积缩减。HCC存储单元高度与列IO单元高度比为5:4,使得5行列逻辑单元可与4行存储单元高度切片对齐,进一步节省面积。
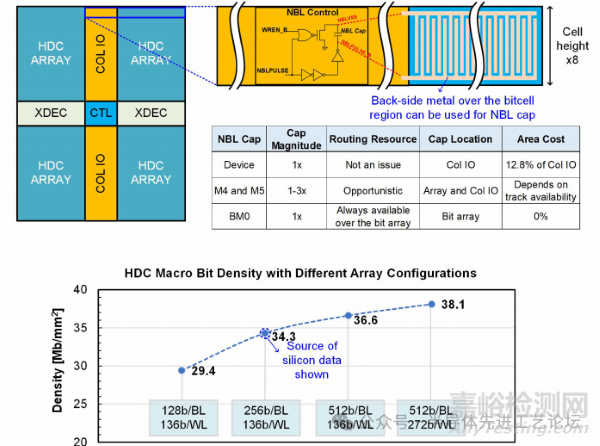
图29.2.5:阵列下方背面金属电容构建的NBL电容(无额外面积占用,上图)及不同阵列配置下的HDC宏单元密度(下图)。
图29.2.6展示了-10℃下的实测硅片结果。94.5Mb大电流(HCC)阵列在未采用任何辅助电路的情况下,其90%分位最低工作电压(VMIN)较基准降低24mV。相较于基于FinFET的设计[4]——其需同时采用字线欠压驱动(WLUD)读取辅助技术与瞬态电压崩溃(TVC)写入辅助技术。仅采用负位线(NBL)写入辅助技术时,94.5Mb高密度(HDC)阵列的90%分位最低工作电压(VMIN)较基于FinFET的设计[4](需同时使用字线欠压驱动WLUD与瞬态电压崩溃TVC[8]辅助技术)降低68mV。在95%分位的高要求下,HCC与HDC的VMIN均低于设计规格80mV以上,展现出充足的设计余量。电压-频率Shmoo图测试结果表明,采用负位线(NBL)写入辅助技术的94.5Mb高密度(HDC)阵列(由2048×64m4宏单元构成),其最低工作电压(VMIN)较基准降低超过200mV。
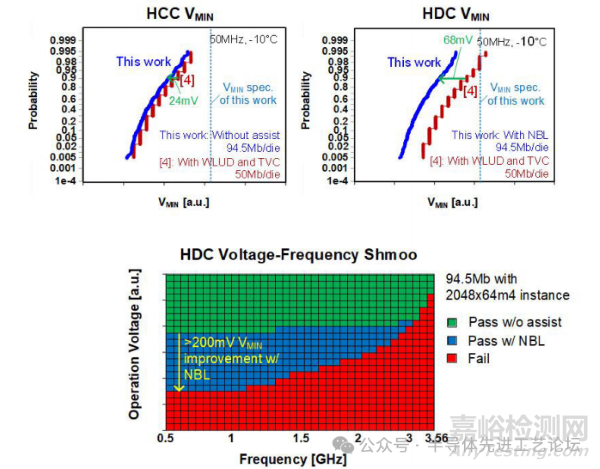
图29.2.6:实测最低工作电压(VMIN)分布(上图)及HDC电压-频率测试芯片Shmoo图(下图)。
图29.2.7展示了采用英特尔18A工艺制造的测试芯片晶圆照片,该芯片在业界首次集成了RibbonFET CMOS、背面供电及PowerVia技术。其中,94.5Mb HCC与HDC阵列由支持负位线(NBL)写入辅助技术的2048×64m4宏单元构成。

图29.2.7:测试芯片晶圆照片,重点标注了94.5Mb HCC与HDC阵列。该芯片采用RibbonFET及PowerVia技术制造。
参考文献
[1] W. Hafez et al., “Intel PowerVia Technology: Backside Power Delivery for High Density and High-Performance Computing”, IEEE VLSI, 2023.
[2] M. Shamanna et al., “E-Core Implementation in Intel 4 with PowerVia (Backside Power) Technology”, IEEE VLSI, 2023.
[3] D. Kim et al., “A 2048x60m4 SRAM Design in Intel 4 with an Around-the-Array Power-Delivery Scheme Using PowerVia”, ISSCC, pp. 278-280, 2024.
[4] Y. Kim et al., “Energy-Efficient High Bandwidth 6T SRAM Design on Intel 4 CMOS Technology”, IEEE JSSC, vol. 58, pp. 1087-1093, April 2023.
[5] T. Song et al., “A 3nm Gate-All-Around SRAM Featuring an Adaptive Dual-BL and an Adaptive Cell-Power Assist Circuit”, ISSCC, pp. 338-339, 2021.
[6] E. Karl et al., “A 4.6GHz 162Mb SRAM Design in 22nm Tri-Gate CMOS Technology with Integrated Active Vmin Enhanced Assist Circuitry,” ISSCC, pp 230-231, 2012.
[7] J. Chang et al., “A 5nm 135Mb SRAM in EUV and High-Mobility-Channel FinFET Technology with Metal Coupling and Charge-Sharing Write-Assist Circuitry Schemes for High
Density and Low-VMIN Applications”, ISSCC, pp. 238-239, 2020.
[8] Z. Guo et al., “A 23.6Mb/mm2 SRAM in 10nm FinFET Technology with Pulsed PMOS TVC and Stepped-WL for Low-Voltage Applications”, ISSCC, pp. 196-197, 2018.

来源:半导体先进工艺论坛
关键词: 晶体管