
嘉峪检测网 2025-04-05 16:59
导读:本文结合国家药监局信息中心推进大语言模型应用的初步实践,分析药品监管领域应用大语言模型所需的基础考量,初步提出了药品监管大语言模型一体化建设框架与实践路径。
摘 要Abstract
近年来人工智能(AI),尤其是大语言模型技术的快速发展,为药品监管领域带来了新的机遇与挑战。本文结合国家药监局信息中心的初步实践,探讨了药品监管领域应用大语言模型的基础考量,提出了一体化建设框架与实践路径。文章首先分析了数据、算力和算法三大基础要素的重要性,梳理了数据质量、算力成本和算法适用性在模型应用中的关键作用;提出了一体化建设框架,建议通过国家与省级药品监管部门的协同合作,构建统一且可扩展的大语言模型应用体系,避免重复建设和资源浪费;最后展示了大语言模型在药品注册形式审查场景中的具体案例及实际应用成效,并展望了未来药品监管大语言模型在智能化水平、安全性、合作平台和个性化服务开发等方面的发展前景。
In recent years, the rapid development of artificial intelligence (AI) technology, particularly large language models (LLMs), has brought new opportunities and challenges to the field of drug regulation. This paper, based on the preliminary practices of the Center for Information, NMPA, explores the fundamental considerations for applying LLMs in drug regulation and proposes an integrated construction framework and practical pathways. The article first analyzes the importance of three foundational elements: data, computing power, and algorithms, emphasizing the critical roles of data quality, computing cost, and algorithm suitability in model applications. Next, it proposes an integrated construction framework, suggesting collaborative efforts between national and provincial drug regulatory authorities to build a unified and scalable LLM application system that avoids redundant construction and resource waste. Finally, through a case study on the intelligent review of drug registration documents, the paper demonstrates the practical outcomes of LLM applications and envisions future developments in intelligent systems, safety measures, collaborative platforms, and personalized service development in drug regulation.
关键词 Key words
药品监管;人工智能;大语言模型;一体化建设框架;实践案例
drug regulation; artificial intelligence; large language model; integrated construction framework; case study
近年来,人工智能(artificial intelligence,AI), 尤其是大语言模型技术快速发展,已成为推动各行各业创新和生态系统重塑的强大动力,为相关领域发展注入了无限可能性。在药品监管领域,国家药监局率先印发了《药品监管人工智能典型应用场景清单》[1],明确了15 个重点应用场景。与此同时,相关部门也正在尝试推动AI 技术与核心信息系统的深度融合,通过AI 技术重构现有系统,以实现药品监管业务智能化升级。为高效稳妥推进这一进程,并避免重复建设和资源浪费,不仅需要鼓励相关部门勇于探索,更需要在国家层面进行精心规划和设计,并指导各级药品监管部门有序实践。基于此,本文结合国家药监局信息中心推进大语言模型应用的初步实践,分析药品监管领域应用大语言模型所需的基础考量,初步提出了药品监管大语言模型一体化建设框架与实践路径,并通过案例展示实际应用成效,以期为系统推进药品监管领域大语言模型应用研究和实践提供有益参考。
1. 药品监管大语言模型应用的基础考量
1.1 科学理性看待大语言模型的技术应用
大语言模型是AI 领域的一项突破,它利用具有大量参数的神经网络技术进行高级语言处理。通过自监督学习技术,这些模型能够处理和理解人类语言或文本。其核心是变换器(Transformer)架构,这使得模型在分析一句话时可以同时考虑所有单词,从而更准确地理解整句话的意思,而不仅仅是单独解析每个单词。这种能力让大语言模型在各种自然语言处理任务中表现出色[2]。
大语言模型技术在海量数据处理、智能分析预测以及自动化决策支持等方面已展现出强大的能力[3]。随着技术不断发展,算力价格会持续降低,高性能计算资源将变得越来越普及且容易获取[4] ;模型算法和模型训练工程化方法也在不断优化,大语言模型智能化水平和运行效率将持续提升。在AI 应用治理体系不断完善的背景下,大语言模型技术在提升药品监管科学性和效率方面的潜力不可忽视。
毋容置疑,目前大语言模型技术及应用仍处于早期探索阶段。由于技术成熟度、数据质量、使用成本等多因素的影响, 大语言模型应用存在多方面风险[5] :①技术安全风险,包括提示注入、数据泄漏、不完善的沙盒隔离等。②数据隐私与安全风险,例如,用户数据被用于训练导致隐私信息泄露、模型和数据成为核心资产安全保护难度提升等。③伦理与法律风险,例如,算法偏见与歧视、模型输出错误或虚假信息等。
在药品监管领域, 不应受“ALL in AI”等舆论导向的影响[6]、盲目追求技术潮流,而应秉持科学和理性的态度,紧密结合大语言模型的技术特性、自身实际需求以及风险容忍度,进行审慎评估与规划,确保大语言模型技术的应用能够切实服务于药品监管效能提升。
1.2 高度重视大语言模型技术应用的三大基础
在药品监管领域应用大语言模型技术,必须对支撑其应用的三大基础(数据、算力和算法)具有充分的认识和准备。在结合具体应用场景探讨技术细节之前,需对数据质量、算力需求以及算法适用性进行全面评估,才能确保项目的有效实施和高效运行。
1.2.1 数据基础
数据是大语言模型的基石,其覆盖率、质量、规范程度以及与应用的适配度,直接关系到大语言模型的应用效果和服务质量[7]。当前,AI 语料相关企业不断涌现,多家互联网巨头以及Scale AI 等独角兽企业提供的大规模、高精度AI 数据集服务受到资本市场的高度认可与追捧,充分彰显了高质量数据对于AI 发展的重要性。
药品监管数据涉及大量业务数据、法律法规和专业知识等,具备较高的语义复杂性和领域特异性[8]。大语言模型技术在药品监管领域的应用依赖于这些专业信息和业务数据。专业、高质量的数据不仅是构建有效模型的前提,也是确保模型准确性的重要保障。使用质量参差不齐的数据,将导致大语言模型的训练效果大打折扣,进而影响其在实际应用中的表现。为保障数据的质量,必须制定相关数据标准规范,按要求对数据进行清洗和预处理,对非结构化数据(例如,临床试验报告、药品说明书等)进行数据标注,并持续开展数据质量评估与验证。
1.2.2 算力基础
在开展药品监管大语言模型应用前,必须对大语言模型所需算力的规模有清晰的认知。大语言模型结构相对复杂,动辄数十亿甚至数千亿个参数,训练和推理过程都需要强大的算力资源支持, 包括高性能的图形处理器(graphics processing unit,GPU) 或张量处理器(tensor processing unit,TPU) 集群,这些设备能够提供足够的并行计算能力,以加速模型训练过程,高效进行推理应用。然而,近年来全球算力资源紧缺且价格昂贵,尽管DeepSeek 相关研究成果已显著降低了大语言模型使用的算力成本[9],如深圳市政务云、江西省赣州市政务服务和数据管理局等在政务大模型应用方面,通过采用DeepSeek 技术, 成功将搭建与部署的成本降低至其他模型方案的十分之一[10],但药品监管部门在开展药品监管大语言模型应用时仍需要关注算力成本问题。为了应对这一挑战,项目设计初期必须结合应用场景对算力需求进行详细的预算规划。评估不同阶段的算力消耗,并采取相应的优化措施,例如,利用第三方云资源训练,采用模型剪枝、量化等技术手段,以减少算力开销。
1.2.3 算法基础
在药品监管领域应用大语言模型时,还需要对所使用大语言模型的算法基础具有一定的认知。模型参数量以及是否量化是一个关键因素。较大的非量化模型通常具有更高的表达能力和更强的泛化能力,但也意味着更高的算力成本和更长的计算时间[11]。因此,在选择模型时需要结合业务场景的实际情况,权衡模型大小与实际需求之间的关系,使大语言模型能够在实际应用中更加高效、准确地运行。
不同的应用场景对知识库以及输出样式有着不同的需求,因此需要根据具体的应用需求,选择经过精调后的子领域模型。例如,在处理不良反应报告时,需要引入特定领域知识和规则,以增强模型的理解和预测能力[12] ;而在进行药品监管风险预警时,则需要针对模型输出内容的逻辑性与可解释性进行优化,以提升模型决策结果的可信度,使其更符合实际应用的需要。
1.3 合理规避大语言模型技术应用风险
在药品监管领域应用大语言模型技术时,需要基于对应用风险的深入了解,评估是否使用大语言模型,并选择合适的模型部署方式和服务开放范围[13]。
1.3.1 数据安全
药品监管在保障和促进公众健康中发挥重要作用,该领域相关数据价值高、行政敏感度高[14],因此数据安全是药品监管大语言模型必须坚守的底线。在数据采集和存储阶段,应严格遵守《中华人民共和国个人信息保护法》,确保数据的匿名化和脱敏处理,避免个人隐私和敏感信息的泄露。在数据传输和使用过程中,应遵守《中华人民共和国网络安全法》,采用技术手段,防止数据在传输过程中被截取或滥用。
在模拟训练和推理过程中,数据安全同样至关重要。大语言模型的训练需要海量数据,这些数据可能包含敏感信息。因此,需要在数据预处理阶段进行严格的筛选和过滤,避免敏感数据进入训练集,防止在后续推理阶段出现敏感数据泄露的风险。
模型的部署方式需要根据实际需求谨慎选择。如果服务范围涉及敏感数据或对安全性要求较高,应优先考虑本地化部署或私有云部署,以最大限度减少数据外泄的风险。对于必须使用公有云部署并面向互联网用户提供服务的情况,应选择符合GB/T31168-2023《信息安全技术 云计算服务安全能力要求》、YD/T3157-2016《公有云服务安全防护要求》、GB/T 22239-2019《信息安全技术 网络安全等级保护基本要求》等标准的云服务提供商,并确保其具备完善的数据加密、访问控制和合规性保障措施。
1.3.2 服务质量
药品监管大语言模型应用需遵守《互联网信息服务算法推荐管理规定》,有效应对大语言模型“幻觉”和算法偏见的问题,保障算法透明、公平、可解释,从而保证药品监管AI 服务的质量。
大语言模型有时会产生“幻觉”,即生成的信息看似合理,但实际上并不准确,或其实是虚构的内容[15]。虽然采用检索增强生成(retrieval-augmented generation,RAG)技术在限定范围的知识库内检索生成答案[16]并建立有效的反馈机制,使用户能够报告不准确信息并定期更新模型,有利于减少“幻觉”的发生概率,但在药品监管这一敏感且高度专业化的领域,“幻觉”的发生尤为危险,错误的信息可能导致严重的后果。
算法偏见是指由于训练数据集存在偏差,模型在某些情况下表现出不公平的现象,例如对特定人群、地区、药品或适应症类型的处理不够公正,模型的输出包含歧视性内容或违背社会伦理价值观的观点。虽然通过优化训练数据及训练过程、进行安全对齐并定期审查模型输出等方式可以缓解这类问题[17],但算法偏见仍是服务质量方面的一个重要考量因素。
因此,在药品监管领域引入大语言模型技术时,需要对应用场景所能承受的风险程度进行评估,并采取相应的措施来降低这种风险。
2. 药品监管大语言模型一体化建设框架及实践路径
为统筹推进全国药品监管系统大语言模型应用,避免重复建设和资源浪费,本研究提出了一体化建设框架和实践路径。
2.1 药品监管大语言模型一体化建设框架
药品监管大语言模型的一体化建设框架是指在国家与省级药品监管部门的协同合作下,构建高效、统一且可扩展的大语言模型应用体系(图1)。该框架采用“统建共用、分层细化”的设计理念,即国家药监局的信息化部门负责基础模型、主领域模型以及子领域模型的统一建设与管理,国家与省级药品监管业务部门基于主领域模型、子领域模型进行精调或采取量化、剪枝、蒸馏等技术,构建轻量级专属应用模型[18]。这一模式能够避免各地药品监管部门“重复造轮子”的现象,减少不必要的资源投入,解决技术质量参差不齐等问题,以此提升全国药品监管系统的整体效能。
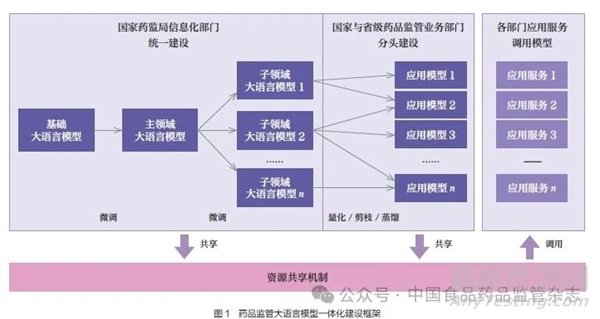
2.1.1 统建共用部分
国家药监局的信息化部门负责基础模型、主领域模型和核心子领域模型的统一建设。作为整个框架的基石, 基础模型通常采用混合专家(mixture of experts,MoE) 框架。该框架具备强大的通用性和扩展性,能够处理复杂的自然语言处理任务。通过MoE 框架,基础模型能够在大规模参数量的情况下保持高效的计算性能,为后续应用提供坚实的技术支撑[19]。主领域模型则是基于基础模型,结合药品监管领域的特定数据进行精调(fine-tuning),形成适用于药品监管垂直领域的核心模型。通过精调技术,模型在深入学习药品监管领域的专业知识后,能够更有效地理解和处理相关任务,特别是在专业术语和法规条款的理解方面有了显著提升[20]。国家药监局相关直属单位,针对特定专业业务场景(例如,药品审评审批、不良反应监测、监督检查等),对主领域模型进行微调,构建针对关键业务场景的核心子领域模型,以更精准服务于药品监管各核心专业领域的具体需求。
主领域和核心子领域模型的统一部署,确保了全国范围内的药品监管系统能够共享同一套高质量的基础模型,有效避免了重复建设和资源浪费。通过这种一体化建设模式,各级药品监管部门可以在统一的技术框架下开展本地化应用,实现技术互通、生态整合和资源共享,全面提升药品监管工作的智能化水平和协同效率。
2.1.2 分层细化部分
在统建共用部分的基础上,国家与省级药品监管业务部门根据自身的业务需求和应用场景,进一步细化模型,构建具体的应用模型。基于主领域模型和子领域模型构建应用模型过程中,主要采用蒸馏技术。国家与省级药品监管业务部门可以通过蒸馏技术从主领域模型和子领域模型中提取关键知识,并将其压缩到规模更小但性能优异的轻量化模型中,使模型能够在边缘设备或本地服务器上快速运行,从而更好地适应地方监管工作的实时性和灵活性要求[21]。
2.1.3 资源共享机制
药品监管大语言模型一体化建设框架的资源共享机制贯穿基础模型、主领域模型、子领域模型以及模型应用的各个层级。模型参数、数据集、模型服务和模型应用等各类资源的共享有利于实现资源的高效利用。这种共享机制能够减少重复建设,降低开发和运维成本,有助于成果的应用和推广,从而全面提升全国药品监管系统的整体效能和智能化水平。
2.2 药品监管大语言模型实践路径
当前,各级药品监管部门正在积极探索大语言模型技术的应用,并逐步将其引入日常监管工作中,但与一体化建设框架的目标相比仍存在一定差距。为确保未来能以较低成本切换到一体化建设框架并实现无缝对接,各级药品监管部门应在现有实践中,将大语言模型应用探索的相关工作置于一体化建设框架中的对应位置,以确保顺利过渡。
2.2.1 渐进式一体化建设路径
在当前的实践中,各级药品监管部门可以根据自身的业务需求,先行构建自有领域模型,并将其应用于具体的监管工作中。这些自有领域模型可以作为未来子领域模型的基础,在经过效果评估和应用验证后,可逐步升级为子领域模型。通过这种方式,各级药品监管部门可以在现有工作基础上,逐步向一体化建设框架靠拢。这种逐步升级的方式不仅能够确保模型的实用性,还能为一体化建设全局赋能奠定基础。
2.2.2 标准化与模块化设计
各级药品监管部门在建设初期就应高度重视标准化与模块化设计。通过统一接口标准,确保系统间的兼容性与互操作性,有效减少技术差异给渐进式一体化框架融合带来的障碍。采用模块化设计,将复杂功能分解为独立模块,便于开发、维护和灵活调用,同时降低未来切换到一体化建设框架的成本。
2.2.3 构建协同创新平台,加速一体化建设进展
各级药品监管部门联合高校与科研机构、大语言模型算法企业以及AI 算力企业等,共同构建一个协同创新平台,是加速药品监管大语言模型一体化建设进展的可行举措。该平台旨在推动各方资源的深度融合与高效协作,为各级药品监管部门的大语言模型应用提供统一且通用的数据基础设施、大语言模型算法服务以及算力支持。借助这一平台,不仅可以有效整合各方优势资源,促进技术创新和经验共享,还能通过统一的技术指导以及一致的技术选型,降低现有系统向一体化建设框架切换的成本,从而显著加快药品监管大语言模型一体化建设进程。
3. 药品监管大语言模型应用初步实践
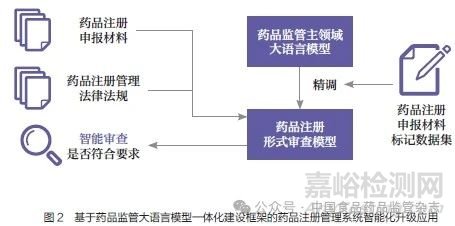
依据药品监管大语言模型一体化建设框架,国家药监局信息中心在业务场景应用落地方面已进行初步探索与实践,并在药品注册形式审查场景中取得了积极进展。通过将大语言模型技术与药品注册管理系统深度融合(图2),初步实现了对申报材料的智能化审核,提升了形式审查工作的效率与准确性。
3.1 需求与目标
在大语言模型引入之前,药品注册形式审查工作面临诸多挑战,包括法律法规的复杂性、申报材料的多样性、数据验证的繁琐性以及审查标准不一致等。这些挑战不仅增加了审查工作的难度,也在一定程度上影响了工作效率和质量,将大语言模型技术引入药品注册形式审查工作成为一种必要且有效的解决方案。利用大语言模型强大的自然语言处理能力和智能化分析功能,可以显著提升审查工作的效率与准确性,同时促进审查标准的统一化,有效解决工作中的痛点。
3.2 实施步骤
大语言模型在药品注册形式审查应用场景的落地实施分为知识库建设、精调模型、系统集成和测试4 个步骤。
3.2.1 知识库建设
知识库建设是保证大语言模型在药品注册形式审查场景中成功落地的基础环节,其核心目标是为模型提供全面、准确的药品注册相关领域知识支持。这一过程专注于收集包括《药品注册管理办法》在内与药品注册直接相关的法律法规、标准文件以及技术指南等,通过深度加工和向量化存储,确保大语言模型能够准确理解和高效应用这些规则,最大限度减少无关信息干扰。其中,向量化存储技术不仅保留了原始文本的语义信息,还具备较强的泛化能力,可帮助模型快速检索和匹配药品注册相关知识[22]。
此外,知识库内容定期更新,确保始终与最新的药品注册相关法律法规、标准文件和技术指南等保持一致,可有效避免因知识滞后导致的误判风险。
3.2.2 精调模型
为了确保药品监管主领域大语言模型能够更好地适配药品注册形式审查的具体需求,有必要对模型进行精调,即通过引入药品注册申报材料样本、历史审查记录等包含标记的业务数据,对基础模型进行针对性训练,使其具备更强的领域知识理解能力。例如,将已通过审查的申报材料作为正例,未通过的材料作为反例,标注其不符合要求的具体原因(包括材料缺失、格式错误或违反特定法规等)。这种带有明确标签的历史数据能够显著提升模型在实际任务中的判断准确性,特别是在药品注册材料完整性检查和合规性判断方面。此外,需要对比精调前后模型的表现,评估其在准确率、召回率等方面的提升效果,确保模型能够满足实际业务需求。通过精调模型,大语言模型在药品注册形式审查场景中的表现得到了显著改善,包括对申报材料的理解能力有所提高,在复杂规则下的判断准确性有所增强等。
3.2.3 系统集成
将大语言模型与现有的药品注册管理系统进行深度集成的核心在于确保大语言模型能够高效、准确地对电子化申报材料进行智能判断和比对。
首先对现有药品注册管理系统的接口进行全面分析,以确定如何最优地将大语言模型嵌入到当前的工作流中;进行自动化或半自动化升级,实现在填写申报内容时,调用大语言模型应用接口,将提交的信息与相关法律法规以及申报材料的上下文内容进行智能判断和比对。
其次,为保证数据的处理效率和安全对接,本项目设计了一个数据适配层,其主要功能是将药品注册管理系统中的数据格式转换为适合大语言模型处理的形式,同时确保数据在传输和处理过程中的安全性与隐私保护。具体而言,所有从药品注册管理系统通过数据适配层传输至大语言模型的数据均经过脱敏处理,从而有效防止敏感信息在传输过程中被截取所造成的隐私泄露。
最后,为了提升用户体验,在系统集成阶段应特别关注界面的设计和交互流程。审查人员在使用系统时,可以直观地看到大语言模型给出的建议和结果,同时可以根据实际情况对这些结果进行调整或确认。这样不仅能提高工作效率,还能增强审查决策的透明度和可信度。
3.2.4 测试
为了验证模型的实际表现和适用性,确保其能够在真实业务环境中稳定运行并满足实际需求,本项目针对基于大语言模型进行智能化改造的药品注册管理系统进行了测试。
为了确保测试结果的全面性和可靠性,本项目采用分层抽样与边界值分析法相结合的策略,构建了多样化的测试数据集,包括:符合药品注册形式审查标准的典型申报材料作为常规案例,用于验证模型在正常情况下的判断准确性和效率;不符合要求的申报材料作为异常案例,例如,材料缺失、格式错误或违反特定法规的情况,用于测试模型识别问题的能力;涉及新的法规条款或特殊审批流程的复杂申报材料作为边缘案例,用于评估模型在处理少见或复杂场景时的表现;收集与历史人工审查记录进行对比分析的数据,验证模型是否能够达到人工审查的标准。
在测试过程中,采用多维度的评价指标来全面衡量大语言模型的表现,包括正确率、安全性、处理速度和可解释性等[23]。正确率用于衡量模型正确判断申报材料合规性的比例,这是测试的核心指标之一;安全性评估用于确保模型在处理敏感数据时能够遵循相关法律法规,保护数据隐私并防止潜在的安全风险;处理速度是指测试模型在不同规模数据集上的响应时间,确保其能够满足实际业务中的效率要求;可解释性用于衡量模型输出结果的透明度,确保其生成的建议和结论能够被审查人员理解和接受。
测试完成后对所有测试结果进行详细分析,并将其作为后续优化的重要依据。对于模型表现优异的部分,将相关策略固化到系统中,确保其在实际应用中的稳定性;针对模型表现欠佳的场景,进一步调整训练数据或优化算法,提升其处理特定任务的能力。
3.3 下一步计划
药品监管大语言模型一体化建设框架具备高度的灵活性和可扩展性。在现有药品注册形式审查模型的基础上,后续可以通过简单切换和升级,将其转化为适用于省级药品监管部门的子领域模型。通过这种方式,各地可以共享统一的技术底座,同时满足个性化需求,避免重复开发,大幅降低资源投入和时间成本。
药品监管大语言模型在药品注册形式审查场景中的应用,为后续将其应用范围扩展至药品全生命周期管理的其他关键环节积累了宝贵的技术经验。通过对临床试验审评审批、生产过程检查和不良反应监测等环节应用场景的探索与实践,药品监管大语言模型将进一步推动药品监管工作的智能化升级,实现从单一环节到全流程的智慧化管理,从而全面提升药品监管效能。
4. 药品监管大语言模型未来展望
智能化水平持续提升。随着算法优化、算力增强以及高质量数据的积累,基于一体化建设框架的药品监管大语言模型将迎来智能化水平的进一步提升,其生成内容的可解释性将持续增强,在自然语言处理、数据分析预测及自动化决策等方面的能力也将得到大幅提升。这将为药品全生命周期管理提供更加精准、高效的解决方案。
大语言模型应用更加安全。随着大语言模型技术的发展与高质量数据集的建设,模型推理的透明度和可解释性将持续提升,不断克服“幻觉”与算法偏见问题,确保所生成结果的准确性和可靠性。同时,随着药品监管领域安全制度的逐步完善,安全防护技术的深化应用,以及从业人员安全培训体系的建立健全,药品监管大语言模型在实际应用中的风险将进一步降低,未来将能够更广泛、更安全地应用于药品监管的各类业务中。
合作平台发展壮大。未来协同创新平台将发展成一个更加开放、包容且充满活力的技术生态系统,吸引更多的合作伙伴积极参与其中。通过持续的技术创新和业务优化,基于一体化建设框架的药品监管大语言模型将不断提升其性能与适用性,从而全方位、深层次地推动药品监管工作的智能化水平整体跃升。
个性化服务开发更加高效。基于基础模型、主领域模型和核心子领域模型,通过结合具体的个性化业务需求进行知识蒸馏,可快速生成适用于特定场景的轻量化模型。随着药品监管大语言模型一体化建设的完善,各级药品监管部门在开发个性化服务时将更加高效,大大节约模型训练、部署的时间,降低所需算力资源。
引用本文
陈锋,吴欣然.大语言模型在药品监管中的应用实践与思考[J].中国食品药品监管.2025.3(254):4-13.

来源:中国食品药品监管杂志